
宮沢賢治『春と修羅』の季節に関連する語彙の分析

この記事について
R Advent Calendar 2022 5日目です。
Rのカレンダー | Advent Calendar 2022 - Qiita
ldccrとgibasaという自作Rパッケージの紹介をかねて、tidytextっぽいやり方によるテキスト分析をやります。
本家のText Mining with Rでは、英語のtidyなテキストデータ(tidy text)について、感情語を収録している辞書とinner_joinすることによって感情分析(というか単語のネガポジを判定するやつ)をおこなっているセクションがあります。この記事では、それと似たような感じで、日本語のtidyなテキストデータと季語を集めた「季寄せ」辞書とをinner_joinすることによって、テキストの季節感みたいなものを調べるというのを試してみます。
使用するデータ
題材としては、宮沢賢治『春と修羅』を使用することにします。『春と修羅』は賢治の生前に刊行された唯一の詩集ですが、刊行された時期によって収録内容の異なる第一集から第三集までがあり、青空文庫でもこれらいくつかのバージョン違いが公開されています。
ここでは、第一集にあたる図書カード:『春と修羅』のテキストファイルを使用します。
青空文庫のテキストファイルをRでダウンロードする手段は何でもよいのですが、ldccrパッケージでもそういう機能を用意しているので、それを使います。
このテキストには、詩の本体のほかに、それぞれの詩のタイトルや、「(一九二二、一、六)」といったかたちの詩の制作日が書かれています。完璧ではないのですが、これを無理やりいい感じに整形します。
require(dplyr)
require(ggplot2)
txt <- ldccr::read_aozora(
"https://www.aozora.gr.jp/cards/000081/files/1058_ruby_4709.zip",
directory = tempdir()
) |>
readr::read_lines() |>
tail(-5) ## 目次の後の表題と作者名をとる
txt <- subset(txt, !txt %in% txt[60:61]) ## 序の後の表題と作者名をとる
idx <- stringr::str_which(txt, "大正十三|一九二[二三]")
corp <- data.frame(doc_id = NULL)
corp[c(1, idx + 1), "doc_id"] <- c(1, idx + 1)
corp <- corp |>
slice_head(n = -1) |>
mutate(
doc_id = coalesce(doc_id, 0),
doc_id = cummax(doc_id),
text = txt,
doc_id = text[doc_id],
row_num = row_number()
) |>
filter(!row_num %in% c(1, idx + 1)) |>
select(-row_num)
rm(txt)
これは、次のようなかたちのデータになります。
head(corp)
#> doc_id text
#> 1 序 わたくしといふ現象は
#> 2 序 仮定された有機交流電燈の
#> 3 序 ひとつの青い照明です
#> 4 序 (あらゆる透明な幽霊の複合体)
#> 5 序 風景やみんなといつしよに
#> 6 序 せはしくせはしく明滅しながら
RでのMeCabとUniDicの利用
このテキストデータは見てのとおり、旧仮名づかいで書かれています。青空文庫の図書カードによると、新字旧仮名だそうです。そこで、ここでは丁寧に、MeCabとUniDicを使って解析することにします。
『春と修羅』は文語ではないので、古文用UniDicSのうち、旧仮名口語UniDicを使います。具体的には、UniDic-202203_60b_qkanaとして配布されている辞書です。
同梱されているrewrite.defによると、この辞書は次のような25属性をもっています。
features <- c(
"pos1",
"pos2",
"pos3",
"pos4",
"cType",
"cForm",
"lForm",
"lemma",
"orth",
"pron",
"kana",
"goshu",
"orthBase",
"pronBase",
"kanaBase",
"formBase",
"iType",
"iForm",
"iConType",
"fType",
"fForm",
"fConType",
"aType",
"aConType",
"aModType"
)
これらの辞書の属性のなかから、「語彙素表記(lemma)」「書字形出現形(orth)」と「書字形基本形(orthBase)」を取りたいと思います。これはgibasaを使って次のように実現できます。ちなみに、このUniDicはdicrcファイルが.dicrcというファイル名になっているので、dicrcにリネームしてからでないとgibasaでは使用できない点に注意してください。
gibasa::gbs_tokenize(
" 石炭をばはや積み果てつ。中等室の卓のほとりはいと静にて、熾熱燈の光の晴れがましきも徒なり。",
sys_dic = path.expand("60b_qkana")
) |>
gibasa::prettify(
into = features,
col_select = c("pos1", "lemma", "orth", "orthBase")
)
#> doc_id sentence_id token_id token pos1 lemma orth
#> 1 1 1 1 空白
#> 2 1 1 2 石炭 名詞 石炭 石炭
#> 3 1 1 3 をば 助詞 をば をば
#> 4 1 1 4 はや 副詞 早 はや
#> 5 1 1 5 積み 動詞 積む 積み
#> 6 1 1 6 果て 動詞 果てる 果て
#> 7 1 1 7 つ 助動詞 つ つ
#> 8 1 1 8 。 補助記号 。 。
#> 9 1 1 9 中等 名詞 中等 中等
#> 10 1 1 10 室 接尾辞 室 室
#> 11 1 1 11 の 助詞 の の
#> 12 1 1 12 卓 名詞 卓 卓
#> 13 1 1 13 の 助詞 の の
#> 14 1 1 14 ほとり 名詞 辺 ほとり
#> 15 1 1 15 は 助詞 は は
#> 16 1 1 16 いと 副詞 いと いと
#> 17 1 1 17 静 形状詞 静か 静
#> 18 1 1 18 に 助動詞 だ に
#> 19 1 1 19 て 助詞 て て
#> 20 1 1 20 、 補助記号 、 、
#> 21 1 1 21 熾熱 名詞 熾熱 熾熱
#> 22 1 1 22 燈 接尾辞 灯 燈
#> 23 1 1 23 の 助詞 の の
#> 24 1 1 24 光 名詞 光 光
#> 25 1 1 25 の 助詞 の の
#> 26 1 1 26 晴れがましき 形容詞 晴れがましい 晴れがましき
#> 27 1 1 27 も 助詞 も も
#> 28 1 1 28 徒 形状詞 徒ら 徒
#> 29 1 1 29 なり 助動詞 なり-断定 なり
#> 30 1 1 30 。 補助記号 。 。
#> orthBase
#> 1
#> 2 石炭
#> 3 をば
#> 4 はや
#> 5 積む
#> 6 果てる
#> 7 つ
#> 8 。
#> 9 中等
#> 10 室
#> 11 の
#> 12 卓
#> 13 の
#> 14 ほとり
#> 15 は
#> 16 いと
#> 17 静
#> 18 だ
#> 19 て
#> 20 、
#> 21 熾熱
#> 22 燈
#> 23 の
#> 24 光
#> 25 の
#> 26 晴れがまし
#> 27 も
#> 28 徒
#> 29 なり
#> 30 。
gibasa::tokenizeで、同様にして、データフレームのtext列を形態素解析します。
なお、今回使用する『春と修羅』はそれほど巨大なテキストではありませんが、UniDic-202203_6b_qkanaがディスク上のサイズで800Mbくらいある大きな辞書だからか、この形態素解析にはそれなりにメモリを食います。ここではとくに何の工夫もしていませんが、手もとで実際に解析したところ、5,200,000トークンほどのtidyなテキストデータにするのに、やや時間を要しました。
toks <- corp |>
gibasa::tokenize(sys_dic = path.expand("60b_qkana")) |>
gibasa::prettify(
into = features,
col_select = c("pos1", "lemma", "orth", "orthBase")
) |>
filter(!pos1 %in% c("空白", "補助記号"))
次のような感じに分かち書きできています。
filter(toks, doc_id == "冬と銀河ステーシヨン") |>
gibasa::pack(orth) |>
pull(text) |>
stringr::str_sub(end = 200L)
#> [1] "そら に は ちり の やう に 小鳥 が とび かげろふ や 青い ギリシヤ 文字 は せはしく 野はら の 雪 に 燃え ます パツ セン 大 街道 の ひのき から は 凍つ た しづく が 燦々 と 降り 銀河 ステーシヨン の 遠方 シグナル も けさ は まつ赤 に 澱ん で ゐ ます 川 は どんどん 氷 を 流し て ゐる の に みんな は 生 ゴム の 長靴 を はき 狐 や "
TF-IDFによる単語頻度の重みづけ
doc_idごとにlemmaを数えて集計し、TF-IDFで重みづけします。
gibasaではRMeCabと同じ計算式を用いながら、tidytext::bind_tf_idfと同様のスタイルで単語頻度の重みづけができる、gibasa::bind_tf_idf2という関数を提供しています。この重みづけの詳細については、この資料を参照してください。ここでは、IDFとしてidf3(確率的IDF)を使ってみます。
また、後で季語の辞書と結合したいので、lemmaの外来語(「マッチ-match(火)」のようなかたちをしている)を単語だけのかたちにしておきます。
summ <- toks |>
filter(
!pos1 %in% c("助詞", "助動詞"),
!stringr::str_detect(lemma, "[A-Z]$")
) |>
mutate(
lemma = if_else(is.na(lemma), token, lemma)
) |>
count(doc_id, lemma) |>
gibasa::bind_tf_idf2(lemma, doc_id, n, idf = "idf3") |>
mutate(
lemma = stringr::str_remove_all(lemma, "\\-[[:alpha:]()]+")
)
head(summ)
#> doc_id lemma n tf idf tf_idf
#> 1 序 あらゆる 69 0.002994012 4.022368 0.012043017
#> 2 序 インク 69 0.002994012 6.022368 0.018031041
#> 3 序 けれど 69 0.002994012 2.562936 0.007673462
#> 4 序 スケッチ 69 0.002994012 5.022368 0.015037029
#> 5 序 そして 138 0.005988024 3.437405 0.020583265
#> 6 序 つ 345 0.014970060 1.630050 0.024401952
tidyなテキストデータを季語の辞書と結合する
季語の辞書としては、手もとに俳句の季語を収録しているSQLiteデータベースがあったので、それを使います。どうやら以前にどこかのWebサイトから自分でスクレイピングしたデータのようですが、詳細はよくわかりません。
俳句の季語や季題は、新年・春・夏・秋・冬の5カテゴリあります。このデータベースには表記揺れを含めて17,000個くらい季語が収録されていますが、俳句の季語というのはどうやら冬の季語になるし新年の季語にもなるみたいなことがあるらしく、見出し語の数としてはもっと少ないようです。
conn <- RSQLite::dbConnect(
RSQLite::SQLite(),
"kigo.db"
)
kigo_dict <-
tbl(conn, "surfaces") |>
inner_join(tbl(conn, "dict"), by = c("did" = "id")) |>
inner_join(tbl(conn, "seasons"), by = c("season" = "id")) |>
select(kigo, name) |>
rename(season = name) |>
collect() |>
mutate(season = factor(season, levels = c("春", "夏", "秋", "冬", "新年")))
RSQLite::dbDisconnect(conn)
slice_sample(kigo_dict, n = 10)
#> # A tibble: 10 × 2
#> kigo season
#> <chr> <fct>
#> 1 夏沸瘡 夏
#> 2 住吉御弓神事 新年
#> 3 助炭 冬
#> 4 鹽鰤 冬
#> 5 土かぶり 夏
#> 6 網代守 冬
#> 7 貌鳥 春
#> 8 走百病 新年
#> 9 姥鴫 秋
#> 10 芝居仕初 新年
季節ごとの内訳は次のようになっています。夏が多いようです。
kigo_dict |>
count(season)
#> # A tibble: 5 × 2
#> season n
#> <fct> <int>
#> 1 春 3040
#> 2 夏 5609
#> 3 秋 4019
#> 4 冬 2476
#> 5 新年 2232
もっとも、そもそもこうした「季寄せ」の見出し語とUniDicの見出し語を結合するにあたって、両者がまったく同じかたちをしている保証はないのですが、とくにいいアイデアもないのでそのまま使います。
また、そもそもの話というのであれば、もちろん、宮沢賢治の詩に出てくる「季寄せ」の見出し語がつねにその季語と同じ季節感を反映していることばというわけではありません。たとえば、「山」は俳句では夏の季語になりますが、賢治の詩のなかに出てくる「山」ということばが必ずしも夏の山ばかりでないだろうことは容易に想像できます。
ただ、なんとなくおもしろい気がするので、試しに『春と修羅』の全体を通じてよく出てくる季語を季節ごとに集計してみましょう。
kigo_dict |>
inner_join(y = summ, by = c("kigo" = "lemma")) |>
group_by(season, kigo) |>
summarise(
tf_idf = sum(tf_idf),
.groups = "keep"
) |>
group_by(season) |>
slice_max(tf_idf, n = 5) |>
mutate(kigo = reorder(kigo, tf_idf)) |>
ggplot(aes(tf_idf, kigo)) +
geom_col(show.legend = FALSE) +
facet_wrap(~season, scales = "free_y") +
labs(x = NULL, y = NULL)
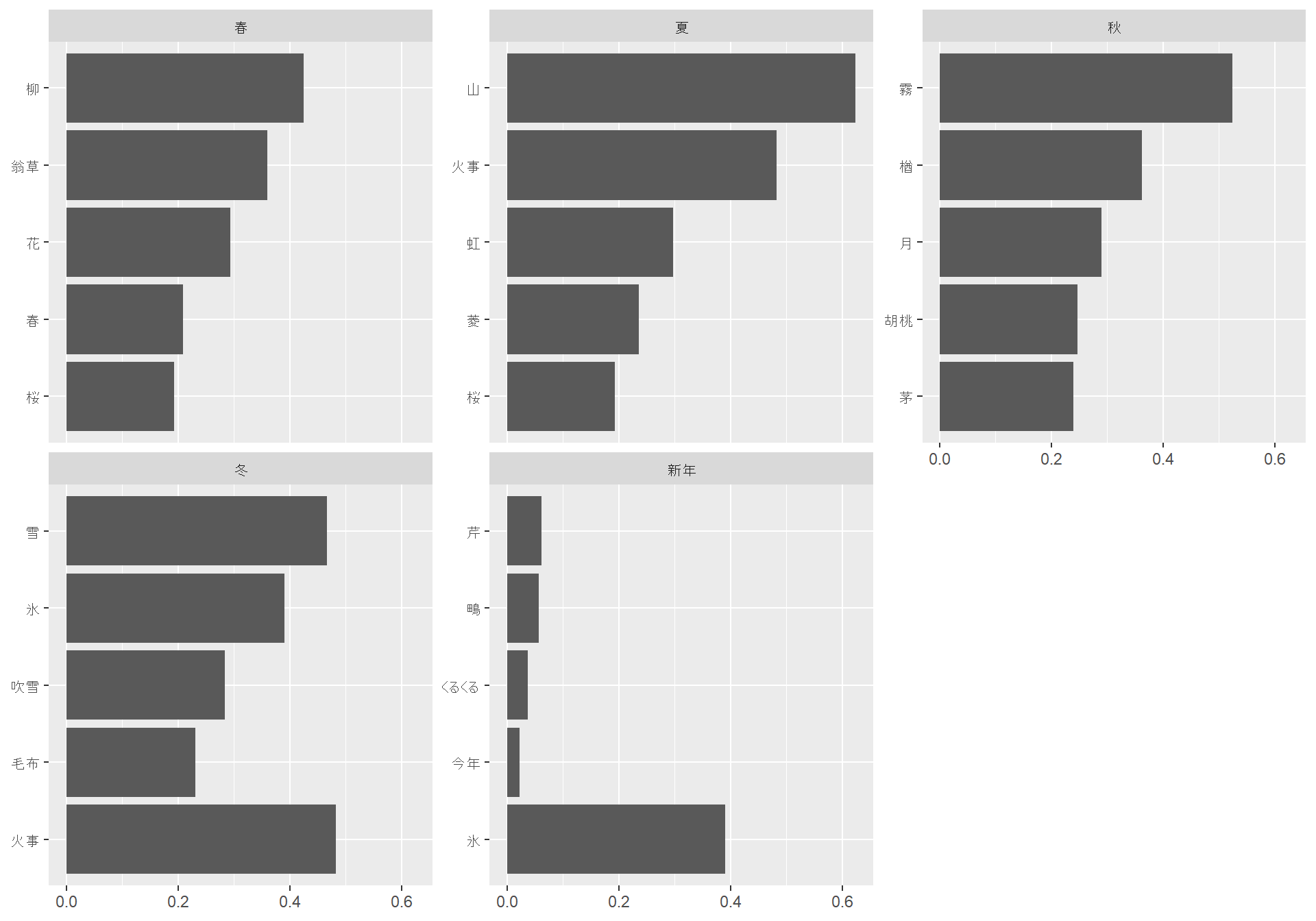
春や冬はなんとなくわかるものの、夏に「火事」が出てくるあたり、ちょっとデータがあやしいような気もします。
次に、作品ごとにどの季節のことばが多そうかを図示してみます。
kigo_dict |>
inner_join(y = summ, by = c("kigo" = "lemma")) |>
group_by(doc_id, season) |>
summarise(
`語種` = unique(kigo) |> length(),
tf_idf = sum(tf_idf),
.groups = "keep"
) |>
ungroup() |>
mutate(grp = ntile(doc_id, 4)) |>
group_by(grp) |>
group_walk(
\(.x, .y) {
g <-
ggplot(
.x,
aes(x = season, y = tf_idf, fill = 語種)
) +
geom_col() +
facet_wrap(~doc_id, ncol = 3)
print(g)
}
)
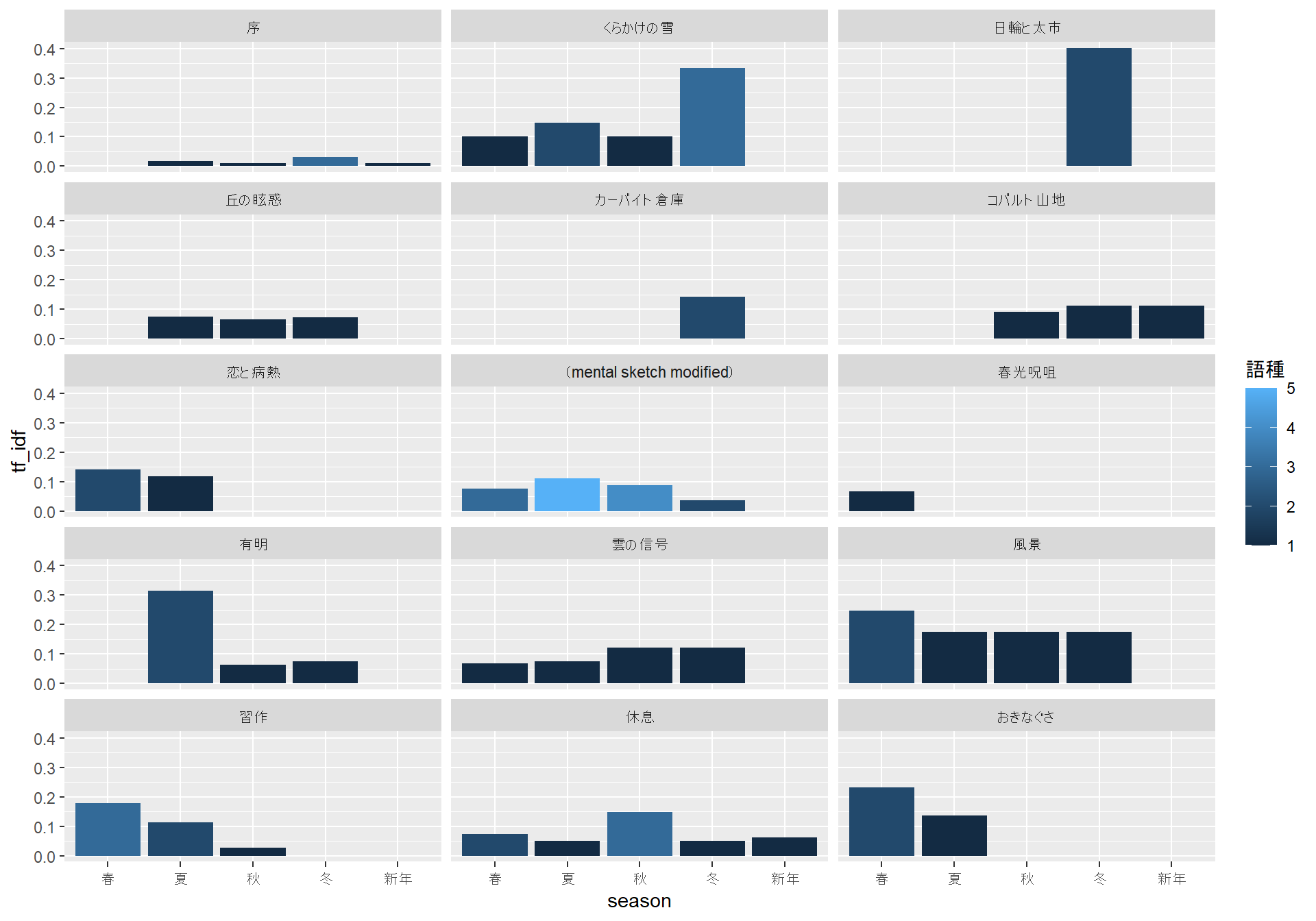
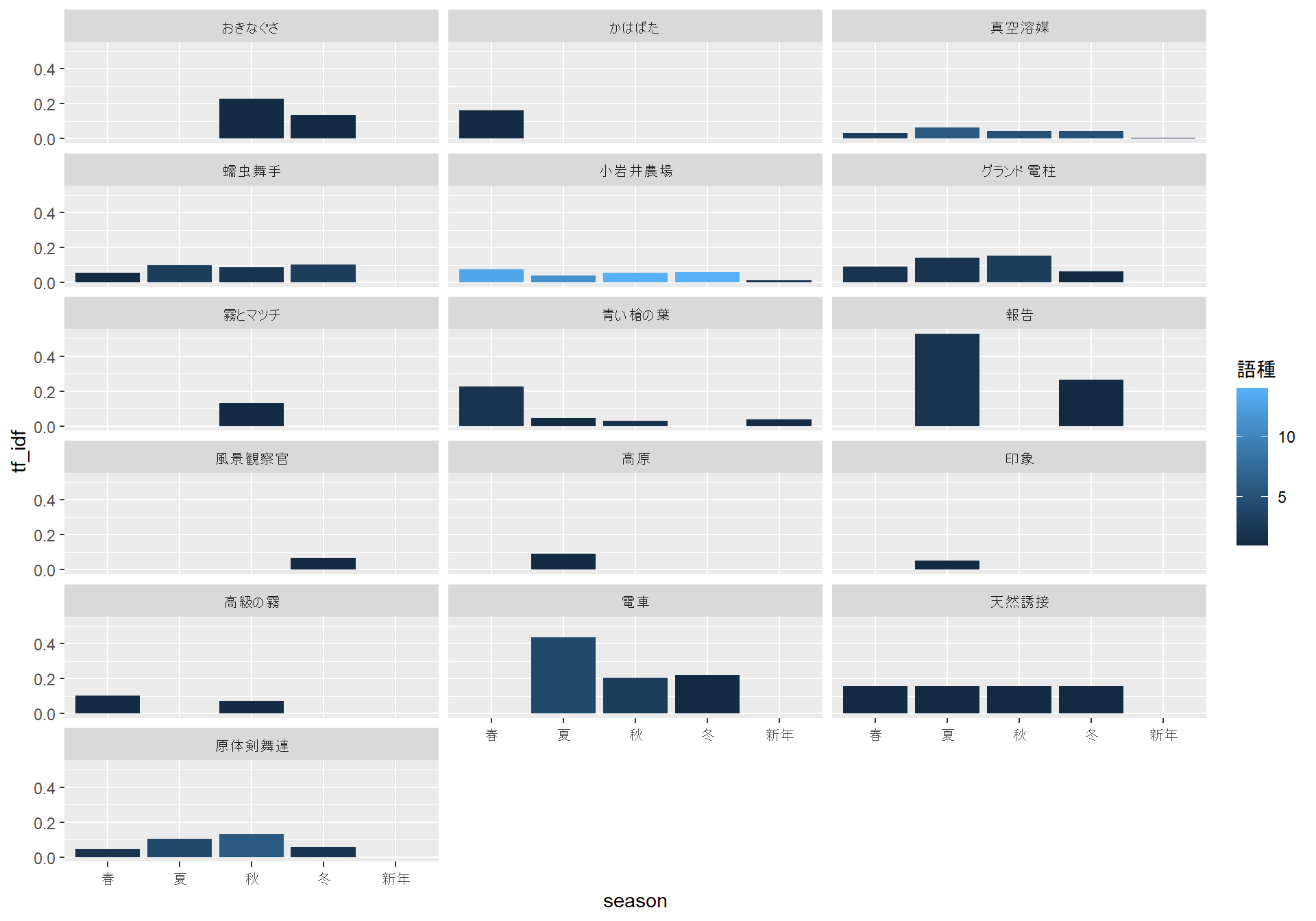
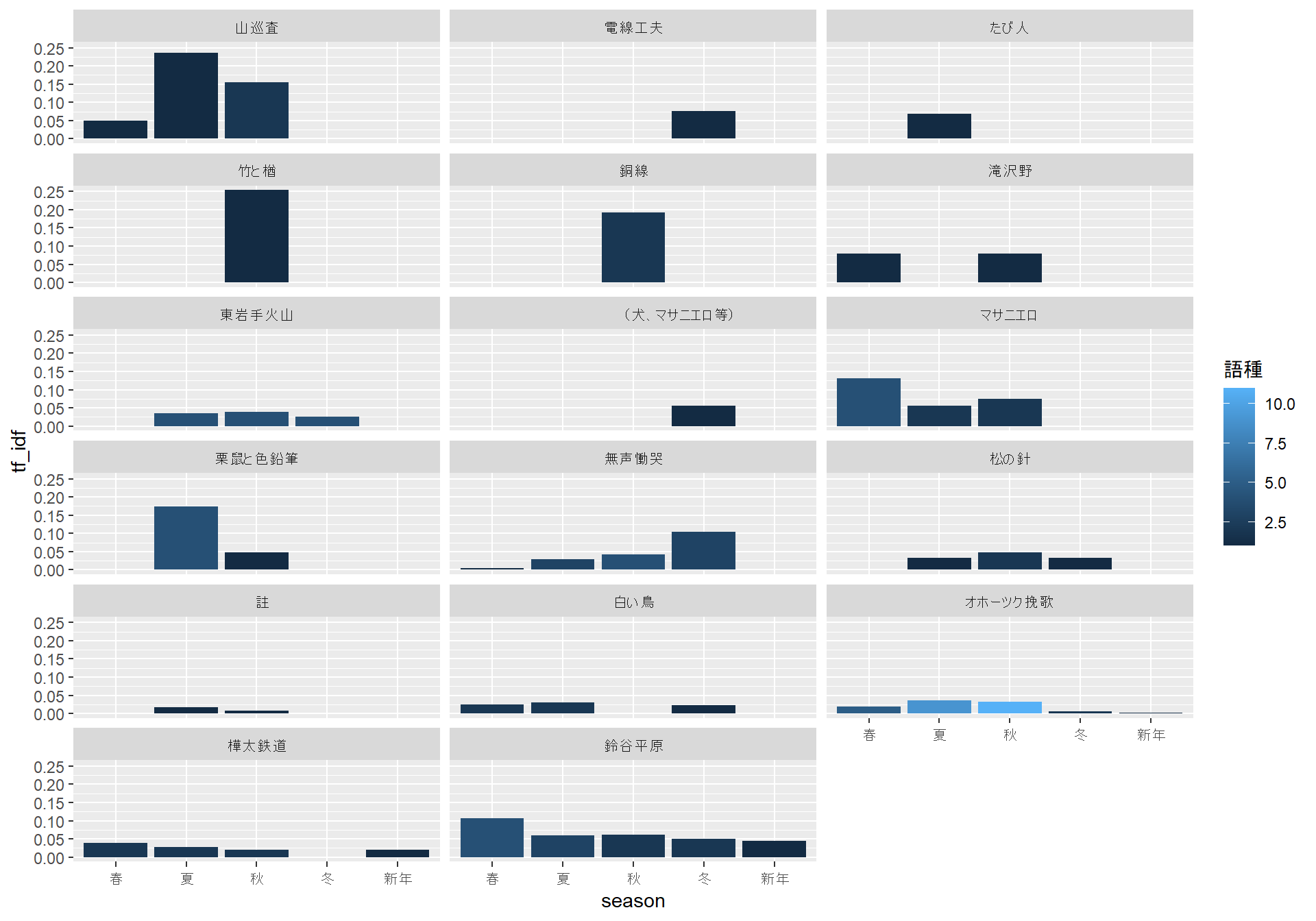
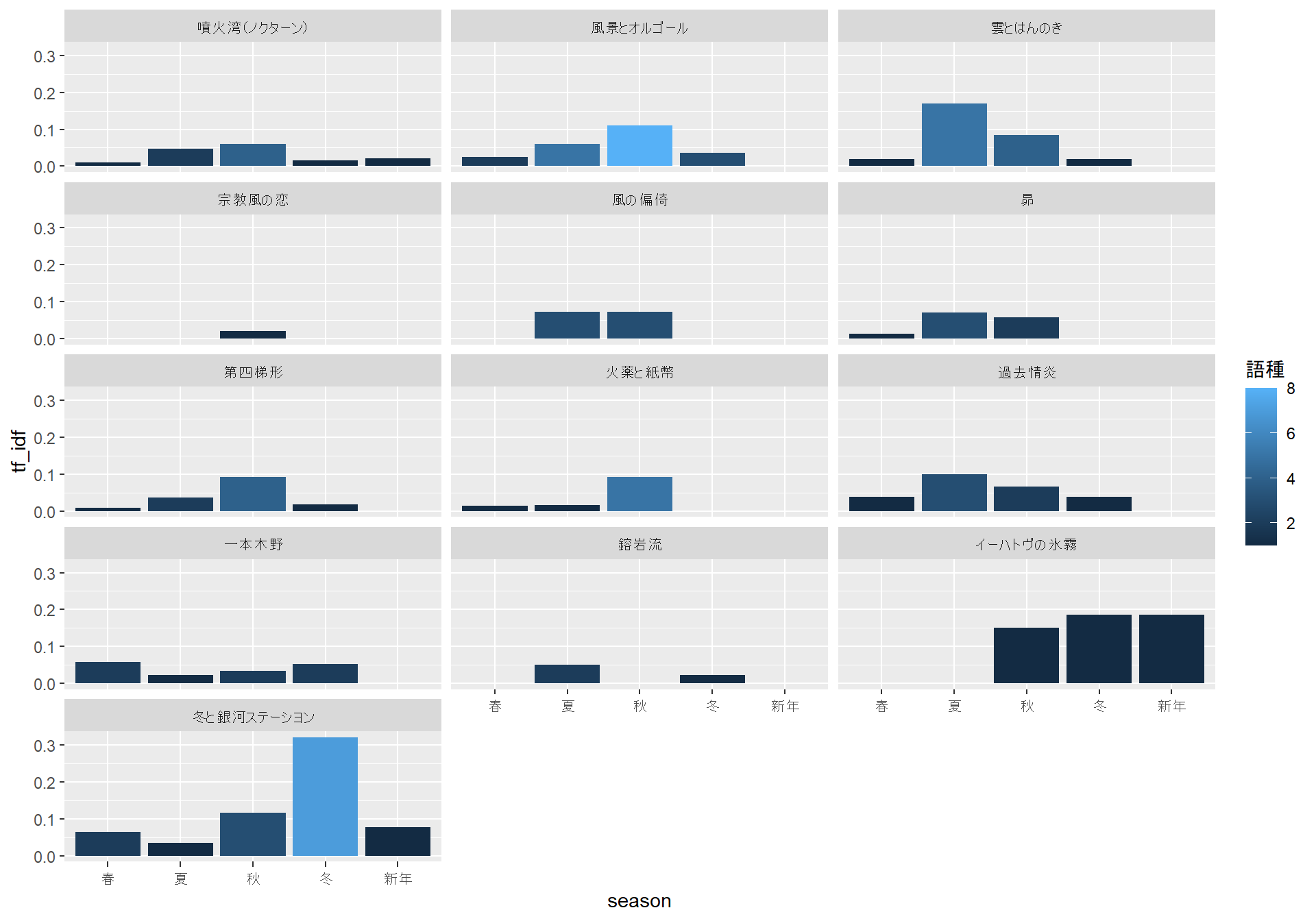
「冬と銀河ステーシヨン」など、明らかに冬なのだろうなという詩では、たしかに冬に関連することばが多くなっているように見えます。一方で、春から冬にかけての季語がまんべんなく出現しているように見える「風景」のような詩もあります。「風景」に関しては、作中に「さくら」や「さつき」といったことばが見えることから、春の詩のような気もしますが、あるいは短い詩のテキストでは季節の差があらわれにくいのかもしれません。
まとめ
この記事では、日本語のtidyなテキストデータに対して、「季寄せ」に収録されている見出し語と突き合わせることで、テキストの季節感のようなものを分析できないか試してみました。
この「季寄せ」のデータ自体がややあやしいことや、俳句の季語の季節感は現代の私たちの四季の区分の感覚とはやや異なっていそうなことなど、注意すべき点はありますが、冬っぽい詩ではちゃんと冬らしいことばが多いように見えるなど、感覚的には悪くない結果がえられたように思います。
この分析だけからではとくに断定的なことはいえませんが、宮沢賢治は岩手の人ですから、詩のなかに冬らしいことばを盛り込むのはやはり得意だったのかもしれませんね。
参考
Photo by Bonnie Moreland in Landscapes