
「短歌地図」を描く(批評とは違う仕方で)

「短歌地図」について
次の記事に「短歌地図」をめぐる主張が書かれている。
短歌で遭難しないために – 砂子屋書房 月のコラム
この記事によると「短歌地図」という言い方は、奥田亡羊による「短歌地図が違う」(『歌壇』2022年1月号)という文章で持ち出されたものらしい。そもそも私は奥田のこの文章を読んでいないし、この用語をめぐる議論を真っ向から深掘りしたいとも感じられなかったのだが、なんというか、おもしろい言い方だなとは思った。
上の記事に書かれている内容から察するに、奥田が「短歌地図」と表現しているものは、現代短歌の世界にはどういった歌人がいて、それぞれどんな作品をつくっているかという世界認識――いわゆる認知地図みたいなニュアンスのものだろうと思われる。この用語を使って奥田が問題化しようとした点は、歌人の受容のされ方にはどうやら世代差があり、とりわけ若い世代では、岡井隆や昭和40年代生まれの歌人があまり読まれていないように見えるということだった、らしい。
そういう「批判」に対する上の記事のスタンスとしては、「短歌地図」が個人ごとに違ってくるのは当然のことであり、だから、むしろ「必要なのは彼我の「地図」が異なるものになってしまう背景を探り、広い世代の歌人が読まれるような環境を整えるための提言や行動ではないか」という箇所だと読める。実際、「短歌地図」というのが現代短歌の世界の認知地図みたいなニュアンスの用語なのだとすると、そうした個人の認識が多かれ少なかれ偏った(奥田の言い方を孫引きするならば「いびつな」)ものになるのは仕方がないことだ。そういう意味においてなら、私たちの「短歌地図」はどこか歪んだものでしかありえないというのは、まさにその通りだと思う。
一方で、注意すべきだと思うのは、何かの議論をするうえで「正しい」世界認識というのが、まったく想定できないわけではないということだ。少なくとも、「短歌地図」が偏ったものであることが問題になるシーンというのはふつうにあるだろうし、それだからこそ、やはり、他の誰かが「遭難」してしまわないよう、短歌のガイドがたくさん書かれればいいよねという話になるのだと思う。上の記事には「こうした形の批判をすることで、「彼」が態度を改めて、“正しい”短歌地図を描くように努力を重ねるとでも思ったのでしょうか」と皮肉っぽい言い方をしている箇所があるが、「正しい」地図というのはね、実際のところ、あるはずなんですよ……。
「正しい」地図とは何か
そこで、この文章では、短歌について「正しい」地図を描くとはどのようなことなのかを考えてみたい。とはいえ、私たちのそれぞれの心のなかにあるだろう、現代短歌の認知地図としての「短歌地図」の話はしない。それは、取り出して見比べたりとかはできないので。だから、ここでは、具体的な短歌をもとにして(現代短歌の世界全体の、とはいかないが)、実際に地図を描いてみようと思う。
ところで、地図とは何だろうか。思うに、地図というのは、そこに描かれている情報を読み取って、任意の要素がどのような位置関係にあるかといった解釈を得るための道具のことである。そうした道具としての地図には、ふつう、複数の要素が描き込まれている(ちなみに、比喩としてではなく、本来の意味での地図についての話をする際には、そうした地図上に描き込まれている要素のことを地物という)。ここでは、そうした複数の要素について、そこにおける要素間の位置関係が意味をもつような仕方で、シンプルに2次元空間に布置した図のことを指して、地図と呼ぶことにしよう。
したがって、たとえば次の図は、ここでいうところの地図である。
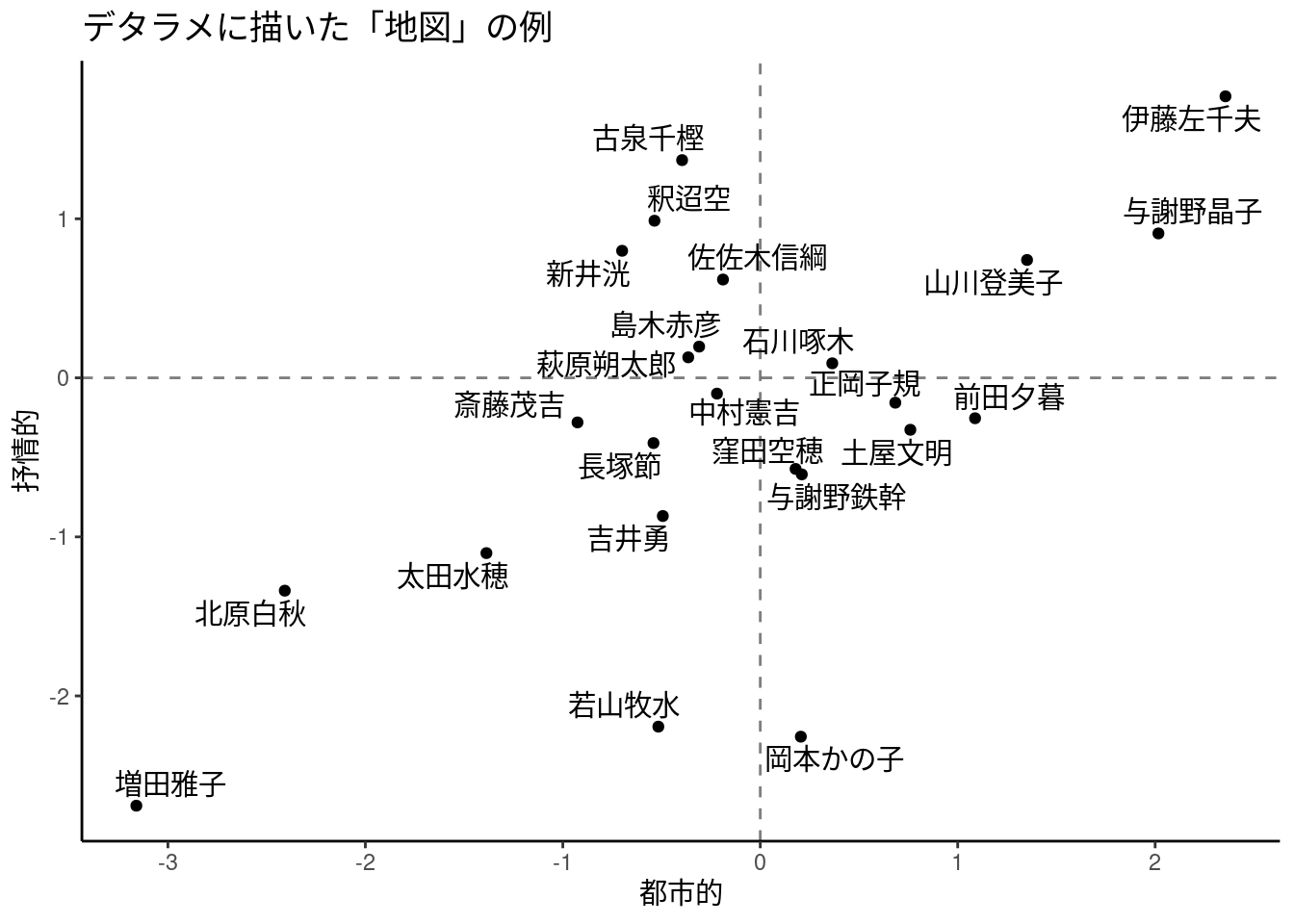
一方で、これは「正しい」地図なのかと訊かれると、疑問符が付く。というか、この地図はそれぞれの歌人に対してまったくデタラメに位置を割り当てて描いたものなので、もちろん「正しい」地図ではない。しかし、それでは、たとえばこの地図を「正しい」ものに作り直すためには、どのようなやり方を取ればよいだろうか。
かいつまんで指摘すると、そもそも、この種の地図には、図示することを目指している「正しい」情報がある。たとえば、近代短歌の詠み手の作風をもとにした位置関係、みたいなことだ。そうした情報を図示しようとするとき、第一に、どんな要素を描き込むかというのがポイントになる。地図に描き込まれる要素は、その地図の目的に照らして、偏りが生じるような方法で選択するべきではないはずだろう。また、それぞれの要素をどのような方法で地図に描き込むかというのもポイントになる。たとえば、それぞれの要素を「都市的」や「抒情的」といった軸を設定して整理しようというのは、そういうアイデア自体がダメなわけではないが、何を基準にマッピングするのかを明確にしなければ、やはりバイアスがかかってしまう恐れがある。
いずれにせよ、ようするに、その地図が図示することを目指している「正しい」情報を読み取れなくなるような、偏りやバイアスが介在している場合、その地図は「正しい」とは言えないものになる。裏返せば、地図を描くプロセスに分析者の個人的な認識に由来する偏りやバイアスが介在していなければ、その地図は「正しい」地図であると言えるだろう。
さて、このように説明してしまうのは簡単だが、そうはいっても、偏りやバイアスが介在しないやり方で地図を描くというのは困難な作業に違いない。個人の「短歌地図」が多かれ少なかれ偏ったものになるのは当然のことなのだから、私たちが印象批評的なやり方で描く地図のなかから、個人の認識に由来する偏りやバイアスを完全に取り去るのはむずかしそうである。
そこで、この文章では、ひとつの試みとして、印象批評的なやり方ではない、主観の入り込む余地をできるだけ取り除いた方法によって地図を描いてみることにする。具体的には、ある短歌投稿サイトに投稿された現代短歌のデータをもとに、計量テキスト分析的な方法によって、短歌の詠み手を2次元空間に布置した図を作成する。また、そうして描いた地図から読み取れそうな簡単な解釈の例を示したうえで、こうした地図のあるべき使い方について注意を述べる。
「地図」を描く
使用するデータ
短歌をもとに地図を描くにあたって、ここでは、短歌投稿サイト「うたの日」のオープン1001日目から1500日目までの500日間に投稿された短歌(74,860首)をスクレイピングして取得したデータを使用する。このデータは、2018年6月ごろに、それぞれの短歌について、詠み手の筆名・投稿された日・投稿された部屋・もらったハートの数(「選」をした際につく+1を除く)と音符の数を収集していたものである。
「うたの日」は2014年ごろから存在するらしい短歌投稿サイトで、「選」のある「歌会」がおこなわれている。ユーザーは、それぞれに一つの題が設定されたページのなかから出詠したいものを選び、決められた時間内に短歌を投稿する。題が設定されたページ一つ一つのことは「部屋」と呼ばれる。短歌の投稿が締め切られると、ある部屋に短歌を投稿したユーザーは、決められた時間内にその部屋で「選」をおこなうことができる。うたの日の「選」は、一人一票を投じることができるもので、この票のことはハートと呼ばれている。また、ハートのほかに、一人で複数の作品に投じることができる票もあり、そちらは音符と呼ばれている。
短歌投稿サイトというのは、もちろん、現代短歌の世界全体と比べるとローカルな世界である。多くの短歌についての言説の関心が、むしろ歌集に収録されているような作品にあるだろうことを考えれば、特定の短歌投稿サイトに投稿された短歌からでは、現代短歌について一般的に確かめたいような情報は得られないかもしれない。しかし、この文章の本旨は、あくまでひとつの試みとして具体的な短歌をもとに地図を描いてみることであり、そのために歌集に収録されているような作品を中心とするデータセットを用意することではない。そこで、ここではとりあえずこのデータだけを対象として、文体的特徴をもとに、一部の詠み手をマッピングすることを目指す。
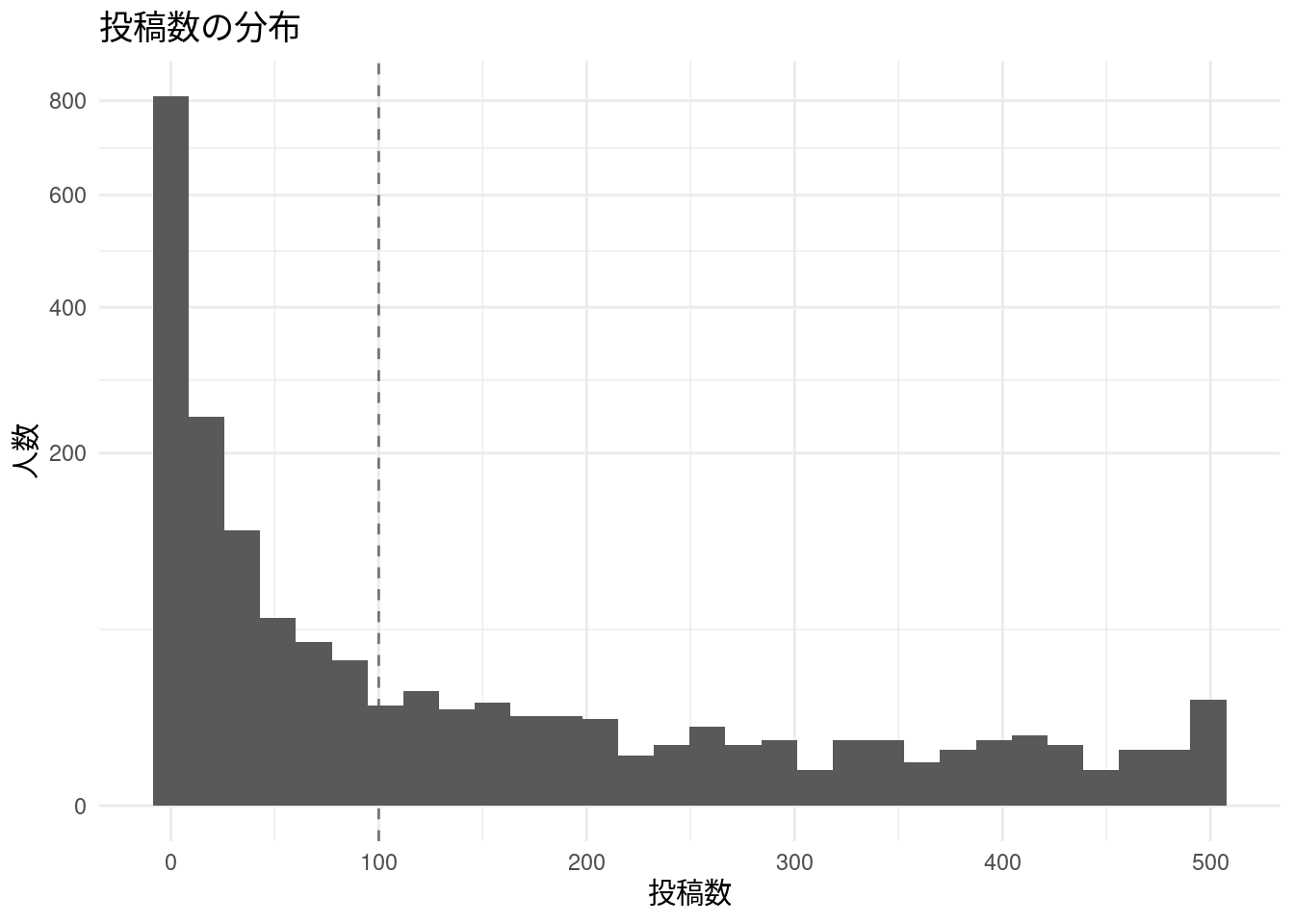
このデータには1524名分の筆名で詠まれた短歌が含まれているものの、この下のグラフから確認できるように、筆名ごとの投稿数にはばらつきがある。文体的特徴をもとに詠み手をマッピングするためには、詠み手ごとにある程度まとまった分量の作品があるほうが望ましいため、ここではデータ全体のうちでも、101首以上の投稿がある詠み手の作品だけを扱う。同一の筆名で101首以上の投稿があったのは1524名中211名分で、抽出された作品の数は延べ55,821首だった(「うたの日」ではシステム的にはまったく同じ文字列の作品を重複して投稿できるため「延べ」としている。なお、文字列として重複している作品であっても、重複を取り除く処理はしていない)。
質的カテゴリーの準備
計量テキスト分析的な方法によって文章や談話の文体を研究する領域は、計量文献学や計量文体論といった呼ばれ方をする。こうした研究領域では、文章や談話の文体を、文法項目の平均的な長さや、使われている語や記号類、また、それらの文字種や品詞といった情報の頻度・比率として特徴量化することによって、分析がおこなわれる。なお、こういった研究領域では、そうした文章や談話の文体を反映していると考えられる指標のことを指して単に「文体的特徴」という。
(なお、計量文体論などが「文体」という用語によって想定している文体概念というのは、この後で扱うような、ある種のテーマとの結びつき方の特徴のようなものというよりも、たとえば「かたい」「やわらかい」「都市的」「抒情的」などといったことばによって形容できるような、そのことばから受ける印象の面での特徴であるように思われる。一方で、ここでは「文体」を「その人の、その人によることばらしさ」くらいにゆるく捉えることにして、両者の意味の「文体」をとくに区別しない)
ここでは、詠み手ごとに作品をまとめ、使われている語に関する文体的特徴にもとづいて詠み手をマッピングすることを考えている。そのため、まず、それぞれの短歌を単語(に近しい単位)に分割する処理をおこなった。また、このとき、とくに注目するべきと考えられる語彙だけを後からフィルタリングするために、それぞれの単語の品詞情報をタグ付けした。具体的には、RのgibasaパッケージとIPA辞書を使用して形態素解析をおこない、KH Coderで採用されている品詞体系にもとづいて品詞情報をタグ付けした。
こうした分析では、分析単位ごとに文体的特徴を要約したデータをクロス表の形にして持ち、対応分析や因子分析にかけることがよくおこなわれる。しかし、とりわけ短歌のようなごく短い形式で、使われている語に注目した分析をしようとした場合、使われている語が多様であるわりに分析単位ごとの分量が少なくなるため、クロス表中で値が0になるセルが多くを占めるようになり、データとして扱いづらくなりがちである。
単純な解決策としては、集計対象とする語彙を何らかの観点(質的カテゴリー)を設定したうえで取りまとめ、観点ごとに文体的特徴として要約することで、クロス表の列数を減らせばよいのだが、任意の語をある観点のもとに取りまとめるには、ふつう、どのような観点を設定すべきかが分析者のなかであらかじめ明確になっている必要がある。一方で、今回のような探索的な分析の段階では、そのような観点を分析に先立って用意することは困難であるケースも多い。
そこで、ここでは、分析対象とする作品に出現する語彙を単語埋め込みをもとにいくつかのテーマ(成分)に分け、それらを質的カテゴリーとして採用することで、分析者による観点の設定を代替することにした。
次の記事で紹介されているように、単語などの埋め込み表現は、独立成分分析にかけると、人間にとって意味の解釈をおこないやすい成分を抽出できることが知られている。
独立成分分析(ICA)を使ってText Embeddingを分析してみた #NLP - Qiita
ここでは、形態素解析にIPA辞書を使った都合から、Wikipedia2Vecの100次元の日本語モデルを使用した。このモデルは、Wikipediaの日本語記事をもとにMeCab+IPA辞書を使いつつ学習されたword2vecモデルで、収録されている異なり語の数は1,593,143語である。
このモデルの先頭から30万語について、まず、分析対象とする作品に出現する語彙のうち、品詞がその他・名詞B・動詞B・形容詞B・否定助動詞・形容詞(非自立)を除くものと照合し、単語埋め込み表現のテーブルを得た。それから、このテーブルを独立成分分析(fast ICA)にかけて、20個の独立成分についての語彙と独立成分スコアとの対応表を得た。
対応分析
こうして得た対応表をもとに、分析対象の詠み手について各成分ごとにスコアの合計を集計して、文体的特徴とした。具体的には、スコアの絶対値が大きい語を使用していれば、その成分によって特徴づけられるテーマに関心があるものと見なし、各成分ごとに、使われている語のスコアの絶対値にそれぞれの粗頻度とIDFをかけた値の和を計算した。ただし、各成分において極性が小さい語には注目しなくてもよいだろうという考えから、ここでは、スコアの絶対値が(すべての成分スコアを通じての)1標準偏差よりも大きい語だけを集計の対象とした。
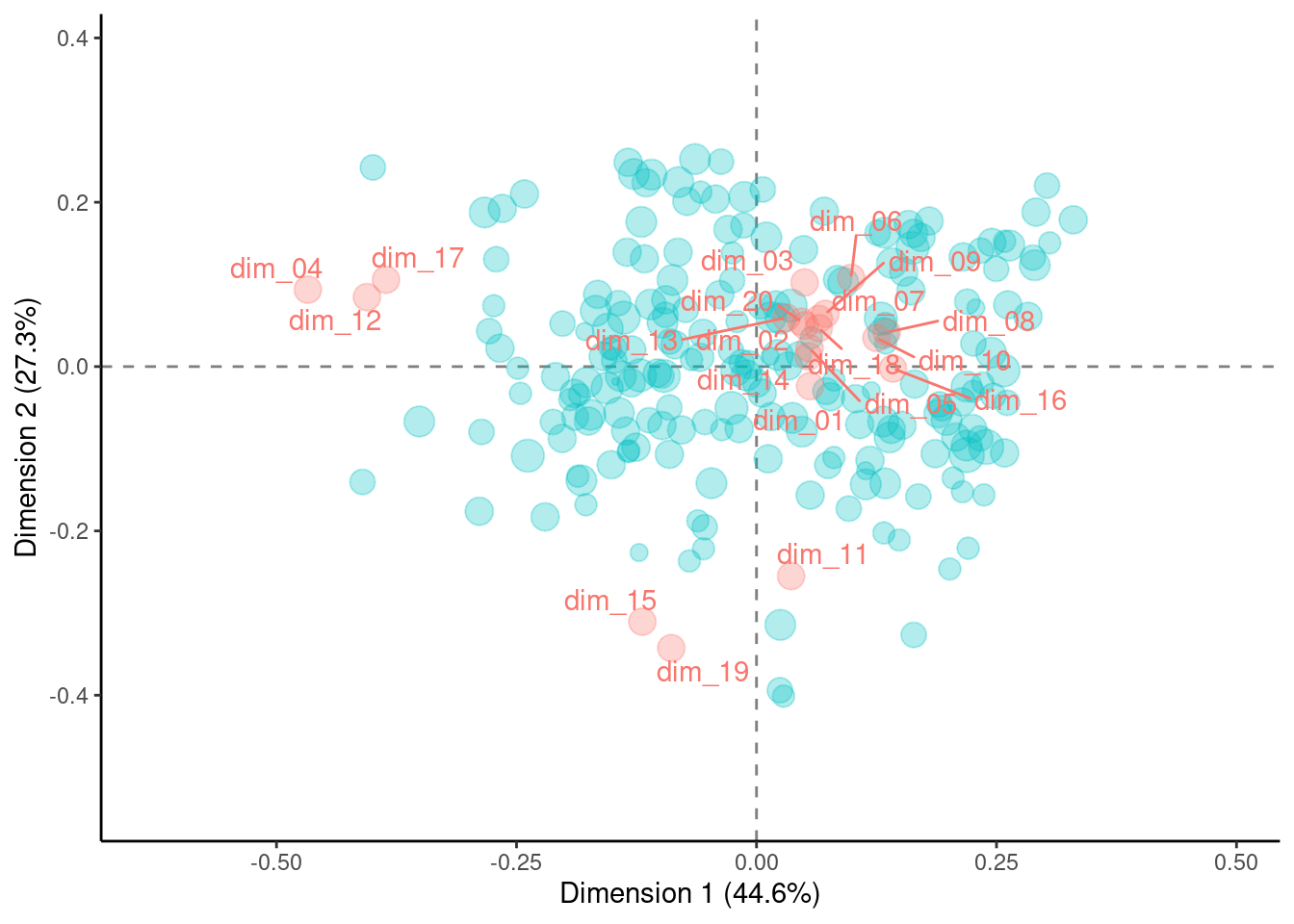
集計したスコアの対数をとったうえで、詠み手✕スコアのクロス表に整形し、対応分析にかけた結果を下に示す。ここでは、得られた第1〜2主軸上での値にもとづいて、詠み手やスコアの関係を2次元空間にマッピングしている。
「地図」の解釈
上の対応分析の結果の地図は、対称マップと呼ばれる方式の同時布置図である。この方式の同時布置図には、
- 偏りの小さい項目は原点付近に、偏りの大きい項目は原点から遠くに布置される
- 互いに関連の強い項目は、原点から見て同一方向に布置される
という性質がある。ただし、この図では、詠み手と詠み手との間の距離や、テーマとテーマとの間の距離には意味がある(近いものはデータとして似ていて、遠いものは似ていない)一方で、詠み手とテーマとの間の距離には意味がないことに注意が必要である。
したがって、たとえば、原点付近に布置されている詠み手ほど、ここにおけるテーマによって捉えられる「癖」が小さく、原点からいずれかの方向に外れている詠み手ほど、その「癖」が特徴的であると解釈できる。また、たとえば、原点からdim_11のある方向に外れている詠み手についてはdim_11と関連があり、(dim_11との距離とは関係なしに)原点から見てこの方向に大きく外れている詠み手であるほど、その関連性が強いらしいと解釈できる。
上の地図を見るかぎり、布置されているテーマについては、原点付近のやや右にかたまっているグループと、原点から左上方向に外れているグループ(dim_04, 12, 17)、下方向に外れているグループ(dim_11, 15, 19)とがある。
原点付近にあるテーマについては、詠み手のあいだでの使われ方にそれほど大きな特徴はないものの、原点から見てわずかに右方向にあるため、同じ方向に布置されている詠み手については、とくにこれらのテーマの語彙によって特徴づけられる「癖」をもっている可能性がある。原点から左上方向や下方向に外れているテーマについてもそれぞれ同じような仕方で解釈が可能であり、かつ、これらのテーマについては、原点付近にあるテーマと比べて、詠み手のあいだでの使われ方により大きなムラがあるかもしれない可能性がある。
それぞれのテーマ(成分)について、スコアの絶対値が大きいものから順に50個ずつ語彙を抽出して表にまとめた。表はここから参照できる。これといった解釈ができそうな成分ばかりではなかったものの、たとえば、対称マップ上で原点から左上方向に外れていたテーマや下方向に外れていたテーマについては、次のように解釈できるかもしれない。
- 左上方向に外れているもの
dim_04: 人物の性格や人となりを形容する語彙dim_12: 解釈しづらいが、しいて言えば「育児」などを連想させる語彙かもしれないdim_17: 仏教や神道などに関連する語彙
- 下方向に外れているもの
dim_11: 性的なニュアンスの語彙dim_15: 介護やケアに関連する語彙dim_19: 容姿や服飾に関連する語彙
これらのテーマの使われ方に他のテーマよりも大きなムラがあるらしい理由は明らかでないものの、たとえばdim_04のように、少なくとも短歌においては単純にそれほど扱われないだろうテーマと、dim_15のように、詠み手の個人的な経験に由来するのでないかぎり扱われにくいだろうと考えられるテーマがあるように思われる。
「地図」の正しい使い方
この文章では、主観の入り込む余地をできるだけ取り除いた方法によって地図を描くことを目指し、短歌投稿サイトに投稿された現代短歌のデータを用いながら、短歌の詠み手と文体的特徴との関係を対応分析によって分析した。対称マップをもとにした解釈として、布置された詠み手やテーマが必ずしも原点付近ばかりに集中していなかったことから、一部のテーマの扱われ方は詠み手によってムラがあるかもしれないことがわかった。
ここで描いた地図は、少なくともその意図としては、分析者の個人的な認識に由来する偏りやバイアスをできるだけ受けないよう注意して作成したものである。そのため、詠み手を文体的特徴によってマッピングすることを目指しつつも、文体を特徴づける観点を設定するにあたっては、どの語彙がどんなテーマと結びつくかを主観的に判断することは避けるようなやり方を採用した。
実際のところ、たとえば、ある種の語彙に注目して、その語は、ある種のテーマについて何かを語るときに用いられやすいといった何らかの傾向を想定することはできる。こうした語彙にまつわる典型的なイメージを想定しつつ、実際にどのようなイメージのそなわっている語を用いるかが詠み手の文体に影響していると考えることは、あながち間違いともいえない。
一方で、実際にどのような語彙をどのようなテーマと結びつけるかは詠み手によって違うだろうと考えるのも自然な想定であり、とりわけ短歌の話をするときには、むしろそうした違いをもたらすものを指してこそ、文体と呼んでいるようにも思われる。このような詠み手や作品ごとに独特な文体の差異に注目する場合、ここで描いた地図によって捉えられる文体的な近さは、しかし、そのような意味における文体的な近さと同値ではないことに注意しなければならない。
たとえば、上で描いた地図からdim_15として捉えられるような介護やケアに関連する語彙を比較的よく用いている可能性のある詠み手と、そうでない詠み手とがいるらしいことが読み取れる。しかし、ここでいう「そうでない詠み手」たちが、実際に介護やケアを題材にした短歌をあまり詠んでいないのかは、もちろん自明ではない。実際、典型的なイメージとして介護やケアに関連するだろう語彙をあまり用いることなく、介護やケアを題材にした短歌を詠むことはおそらく可能だろうし、そういう作品のほうがかえって独特な文体のそなわった表現だと言いたくなるのだが、この地図上で偏りが大きいということは、そういう意味での文体的特徴を捉えているわけではないのである。
「正しい」地図というのは、どこへ持って行っても、その地図そのものから持論を補強するうえで役立つ情報が引き出されるような魔法の道具ではない。それぞれの地図には、図示することを目指している「正しい」情報があり、いかに「正しい」地図といえど、そこから引き出される情報以外は伝えていない。
「正しい」地図は、あくまでも、それを手がかりに実際に作品を読み進めるための助けになるアイテムである。私たちの描く地図そのものが、作品の文体の差異について何がしかの批評を語るわけではない。「正しい」地図を描くのを目指すことは確かにそれ自体魅力的な試みに違いないが、少なくとも私が聞きたいと思うのは、この世界の地図の話ではなく、読者が実際に経験するこの世界での旅の話である。