
Qiitaの「R」の記事の分析

はじめに
この記事は「R言語 Advent Calendar 2023」6日目の記事になる予定です。
R言語のカレンダー | Advent Calendar 2023 - Qiita
さて、Wikipediaの情報によると、R言語のバイナリがはじめて公開されたのは1993年8月のことだったとされています。つまり、2023年はRが世に出されてから30年目の節目の年だったことになります。
そんな長い歴史のあるRが、どのような進化を遂げ、どのようにユーザーコミュニティを形成してきたのかを理解することは興味深い課題です。
30年間にわたるRの利用のされ方を網羅的に把握することは難しいですが、この記事では、特に日本語圏のRユーザーが「R」に関連する技術記事を通じてどのようなトピックに焦点を当て、どのような知見を共有してきたのかをトピックモデルを用いて分析してみます。
分析するデータ
「R」に関連する技術記事として、ここではQiita上で「R」タグが付けられている公開記事の本文を分析します。Qiitaではその他の個人ブログなどと比べて記事にされやすい情報に偏りがある気がしますが、個人ブログなどからもデータを集めてくるのは大変なため、ここではQiitaの記事だけを分析することにします。
あらかじめqiitrパッケージを使ってQiitaのAPI v2を叩き、収集したデータを適当に整形しておきました。
記事の本文としてはrendered_bodyフィールドのなかから、pタグで囲まれているテキストだけを抽出しています。
ここではcld3を使って日本語の文章であると検出できた記事だけを残しつつ(そもそも英語で書かれている、見出しとコードブロックしかないなど、日本語の地の文が存在しない記事はわりとよくある)、その他に記事を書いたユーザーや記事が書かれた年や「いいね」の数など、それっぽい列からなるデータにします。
df <- arrow::read_parquet("data/qiita.parquet") |>
dplyr::as_tibble() |>
dplyr::filter(!stringi::stri_isempty(text)) |>
dplyr::arrange(created) |>
dplyr::mutate(
author = as.factor(author),
year = lubridate::year(created)
) |>
dplyr::select(
doc_id, author, title, text, year, tags,
comments, likes, reactions, stocks
)
データをざっと確認する
投稿された記事の量
「R」タグが付けられている公開記事は、記事を収集した時点で4,600件くらいありましたが、ここで本文が抽出できたのはそのうち4,374件でした。
記事が書かれた年ごとの大まかな分量は、次の図のような感じになります。
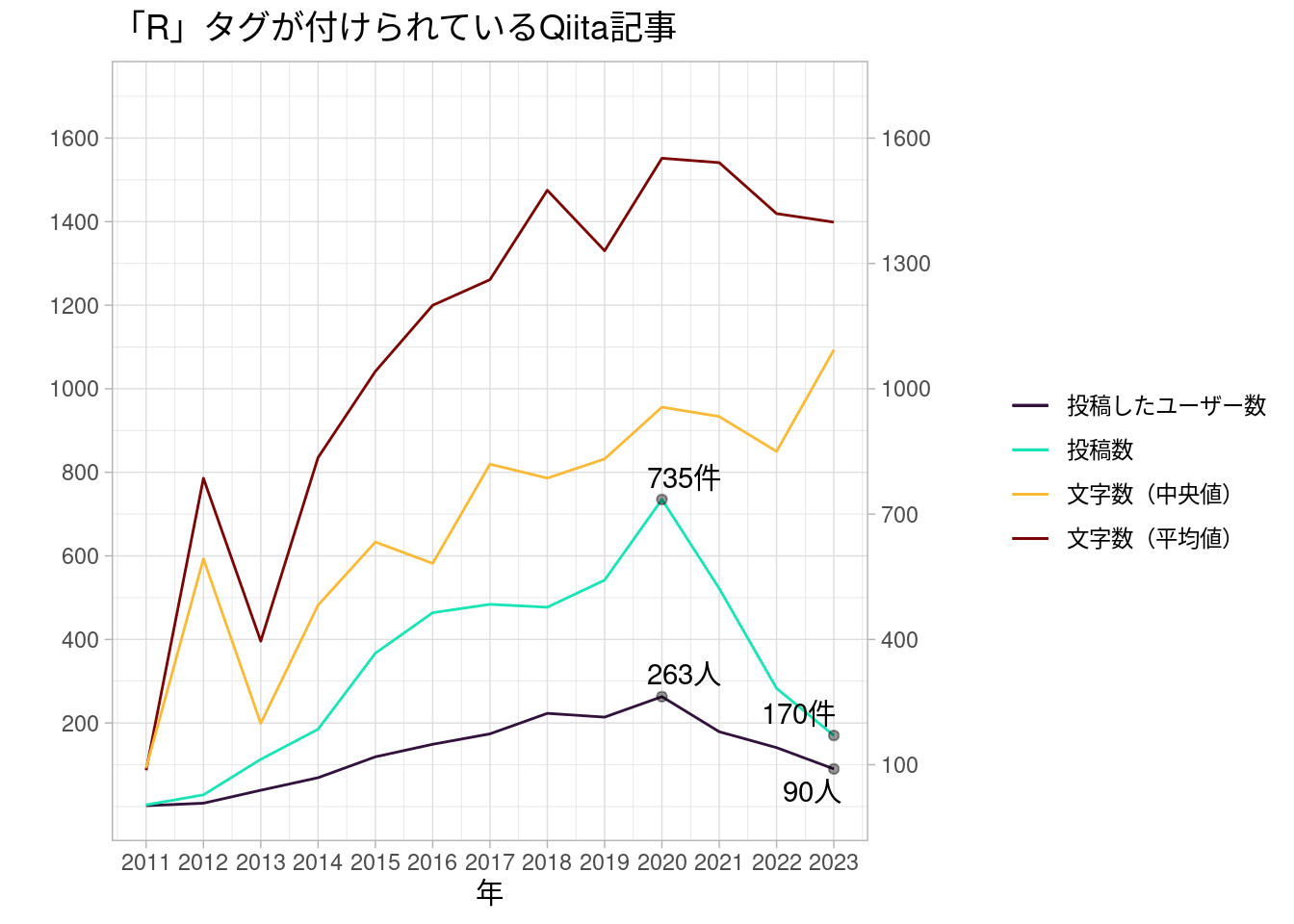
ざっくり見た感じ、2020年までは年ごとの投稿数が順調に増えていたようです。逆になぜ2020年をピークにこんなにわかりやすく減っているのかよくわからないですが、うろ覚えながら、2020年ごろというのは「Qiitaの運営ってどうなの!?」みたいな話が続いていたような記憶もあります。
実際、「いいね」が「LGTM」に変わったり、ユーザーページのリニューアルにともなって「読んだ記事」が見えるようになっちゃったりと、いろいろあったのがこの前後だったようです。そのため、Rの記事を書いていたユーザーの一部も、このころに個人ブログなどに移ってしまったのかもしれませんし、あるいはこの前後でみんなそもそもRの記事を書かなくなったとかなのかもしれません。
2020年ごろをピークに投稿数は減った一方で、記事あたりの文字数はなんとなく増え続けているようです。「R」タグが付けられる記事は減ったものの、長い記事を書くユーザーは比較的長い記事を書いているということでしょうか。
もっとも、Qiitaの記事の「投稿日」ってAPI経由だと書き換えできるようなので(実際、筆者の書いたQiita記事には投稿日のほうが最終更新日より後になっているものがある)、これがどこまで正確なデータなのかはよくわからないというのもあります。
よく共起しているタグ
以下は「R」と一緒に付けられていそうないくつかのタグについて、いい感じに集計した図です。なお、Qiitaそのものは2011年から存在していて、「R」タグが付けられた記事もわりと当初からあるようですが、数が少なかったため、ここでは2013年以降の記事についてのみ集計しています。
df |>
dplyr::filter(year > 2012) |>
tidyr::separate_longer_delim(tags, delim = ",") |>
dplyr::filter(tags != "R") |>
dplyr::count(year, tags) |>
tidytext::bind_tf_idf(tags, year, n) |>
dplyr::filter(tags %in% c(
"RStudio", "ggplot2", "機械学習",
"統計学", "Python", "データ分析", "初心者"
)) |>
ggplot(aes(x = year, y = tf, groups = tags)) +
geom_line(aes(colour = tags)) +
scale_x_continuous("年", df$year |> unique() |> sort()) +
scale_color_viridis_d(option = "turbo") +
labs(title = "関連タグの相対頻度の推移") +
ylab("相対頻度") +
theme_light()
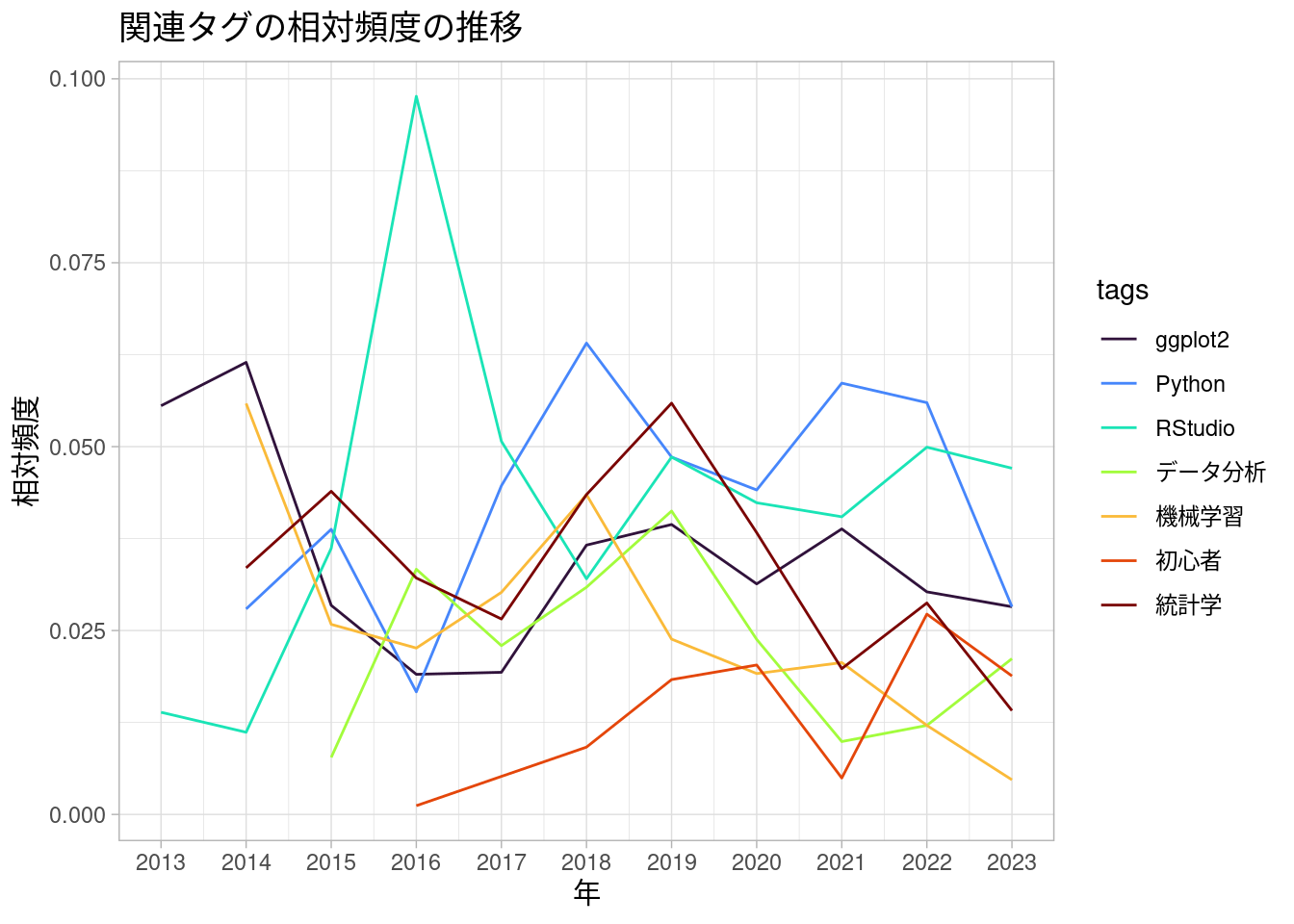
参考までに、RStudioがパブリックベータ版としてはじめてリリースされたのはどうやら2011年2月ごろのことだとされています。Hadleyの「Tidy data」の文章がJournal of Statistical Softwareに載ったのが2014年、magrittrのv1.0.0がリリースされたのも2014年、オライリーから『RStudioではじめるRプログラミング入門』(『Hands-On Programming with R』の邦訳)が出たのが2015年3月、tidyverseのv1.0.0がリリースされたのは2016年9月のことでした。
また、ggplot2がv1.0.0になったのは2015年1月です。ggplot2自体はそれ以前からあって、Hadleyの『ggplot2: Elegant Graphics for Data Analysis』の初版が出たのは2009年、『Rグラフィックスクックブック』(『R Graphics Cookbook』の邦訳)の初版が出たのは2013年11月となっています。
トピックモデル(keyATM)
keyATMの適用
抽出した記事の本文を使って、記事をいくつかのトピックに分類してみます。
トピックモデルの実装としては、ここではkeyATMを使います。このトピックモデルは、Keyword-Assisted Topic Modelsというやつで、分析者があらかじめいい感じに選んだいくつかのキーワードをもとにトピックを用意したりする、なんかそんな感じの半教師ありのやつです(ちゃんと説明できない)。テキストの前処理はquantedaでがんばります。
corp <- df |>
dplyr::filter(year > 2012) |>
dplyr::mutate(period = dplyr::consecutive_id(year)) |>
quanteda::corpus()
2013年以降の記事のみをquantedaのコーパスにして、いい感じに文書単語行列をつくります。実際に使う文書の数は4,289件、異なり語の数は6,413個になりました。
dtm <- corp |>
quanteda::tokens(
what = "word",
remove_numbers = TRUE,
remove_punct = TRUE,
remove_symbols = TRUE,
remove_separators = TRUE,
remove_url = TRUE
) |>
quanteda::tokens_tolower() |>
quanteda::tokens_compound(
quanteda::phrase(c("データ フレーム", "レ イヤー", "ラ スター"))
) |>
quanteda::tokens_remove(
c(
stopwords::stopwords("en"),
stopwords::stopwords("ja", source = "marimo"),
"パッケージ", "データ", "ファイル", "コード", "コマンド"
)
) |>
quanteda::tokens_select(
pattern = "^[\\P{Hiragana}]+$",
valuetype = "regex",
min_nchar = 3
) |>
quanteda::dfm() |>
quanteda::dfm_trim(min_docfreq = 3)
dtm <- quanteda::dfm_subset(dtm, quanteda::ntoken(dtm) > 0)
quanteda::ndoc(dtm)
#> [1] 4289
quanteda::nfeat(dtm)
#> [1] 6413
docs <- keyATM::keyATM_read(dtm)
#> ℹ Using quanteda dfm.
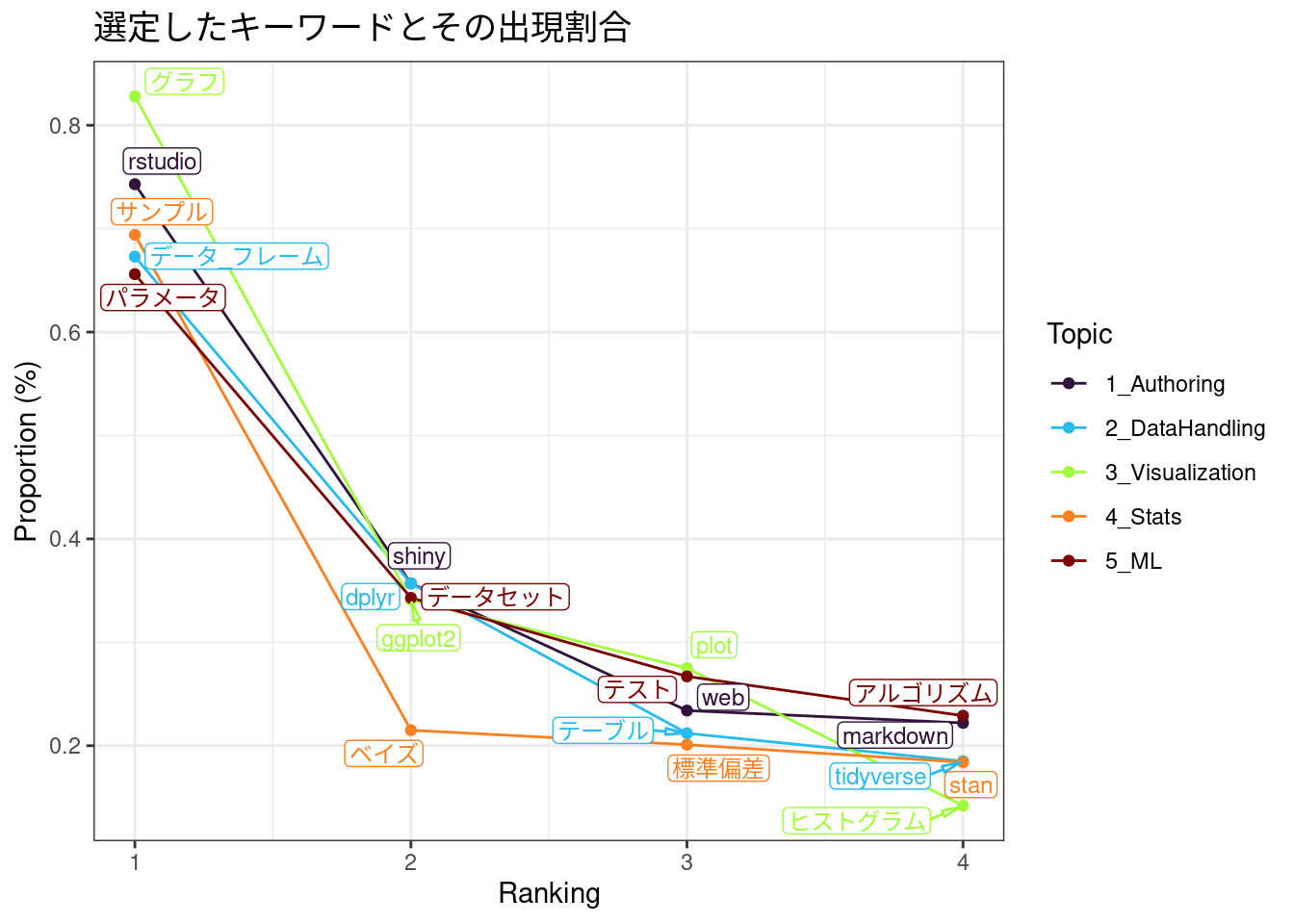
事前知識から用意するトピックとそのキーワードは、ここでは次のような感じにします。さらっと提示していますが、けっこうな時間をかけて選定しました。
keywords <- list(
Authoring = c("rstudio", "shiny", "markdown", "web"),
DataHandling = c("データ_フレーム", "dplyr", "tidyverse", "テーブル"),
Visualization = c("グラフ", "plot", "ggplot2", "ヒストグラム"),
Stats = c("サンプル", "標準偏差", "ベイズ", "stan"),
ML = c("アルゴリズム", "パラメータ", "テスト", "データセット")
)
g <- keyATM::visualize_keywords(docs, keywords = keywords)
g$figure +
labs(title = "選定したキーワードとその出現割合") +
scale_color_viridis_d(option = "turbo")
次のようにkeyATM::keyATMを使います。
out <- keyATM::keyATM(
docs,
no_keyword_topics = 2,
keywords = keywords,
model = "dynamic",
model_settings = list(
time_index = quanteda::docvars(dtm, "period"),
num_states = 5
),
options = list(
store_theta = TRUE,
thinning = 5,
seed = 279
)
)
結果の確認
ここでは、次のような感じの結果になりました。
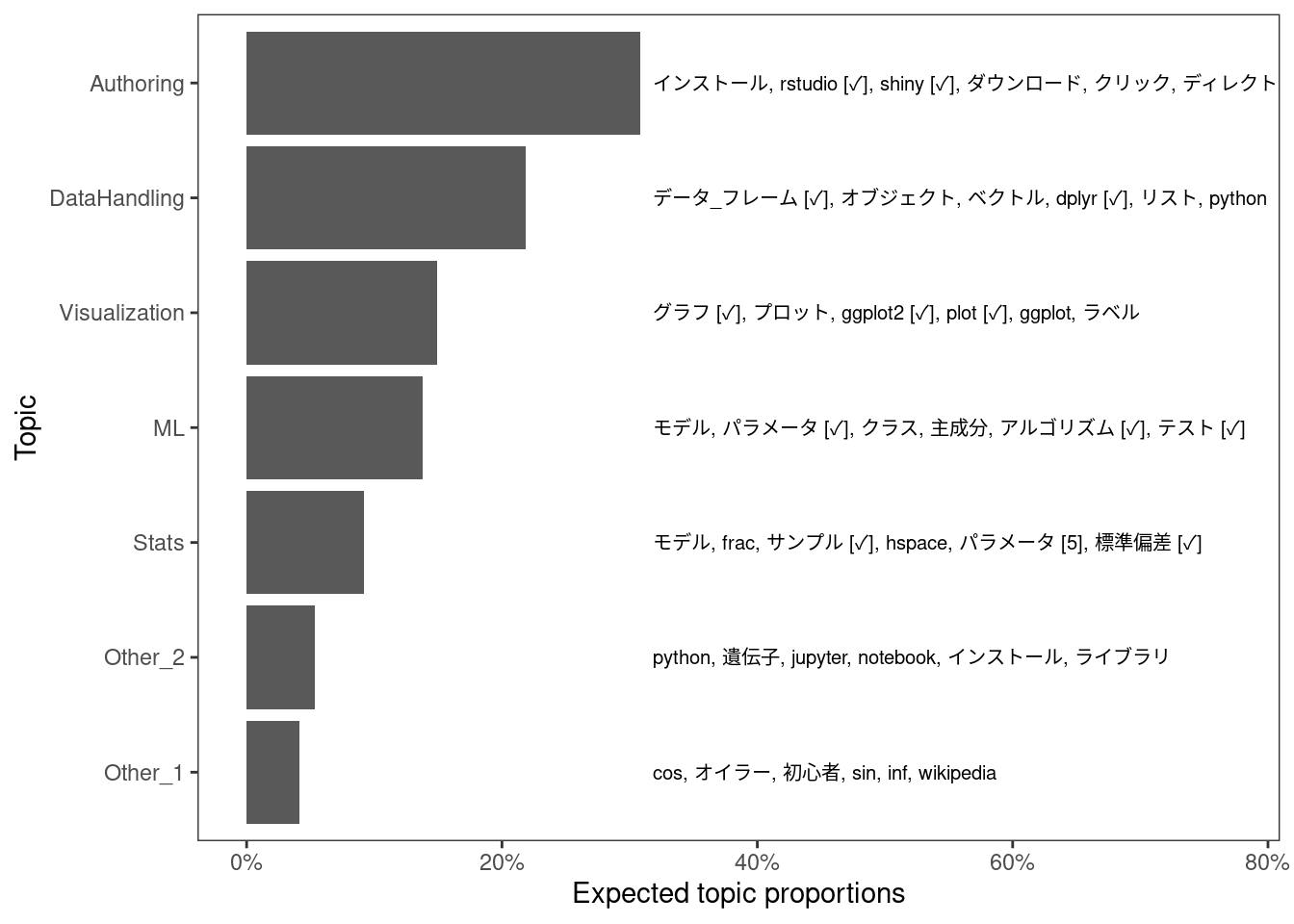
キーワード付きトピックについて、それぞれ出現確率が高い単語を20個ずつ確認します。
keyATM::top_words(out, n = 20, measure = "probability") |>
tidyr::pivot_longer(everything(), names_to = "topic") |>
dplyr::filter(!stringr::str_starts(topic, "Other")) |>
dplyr::group_by(topic) |>
dplyr::group_map(\(x, grp) {
dplyr::pull(x, "value")
}) |>
purrr::set_names(names(keywords))
#> $Authoring
#> [1] "インストール" "rstudio [✓]" "shiny [✓]" "ダウンロード" "クリック"
#> [6] "ディレクトリ" "エラー" "バージョン" "サイト" "スクリプト"
#> [11] "日本語" "docker" "アプリ" "windows" "ページ"
#> [16] "markdown [✓]" "html" "web [✓]" "ソース" "フォルダ"
#>
#> $DataHandling
#> [1] "データ_フレーム [✓]" "オブジェクト" "ベクトル"
#> [4] "dplyr [✓]" "リスト" "python"
#> [7] "テーブル [✓]" "true" "csv"
#> [10] "クラス" "sql" "プログラミング"
#> [13] "data" "メソッド" "exploratory"
#> [16] "カラム" "tidyverse [✓]" "excel"
#> [19] "グループ" "データセット [5]"
#>
#> $Visualization
#> [1] "グラフ [✓]" "プロット" "ggplot2 [✓]"
#> [4] "plot [✓]" "ggplot" "ラベル"
#> [7] "ネットワーク" "デフォルト" "ノード"
#> [10] "ヒストグラム [✓]" "データ_フレーム [2]" "棒グラフ"
#> [13] "csv" "フォント" "ポイント"
#> [16] "カラー" "iris" "都道府県"
#> [19] "サイズ" "オブジェクト"
#>
#> $Stats
#> [1] "モデル" "frac" "サンプル [✓]" "hspace"
#> [5] "パラメータ [5]" "標準偏差 [✓]" "ベイズ [✓]" "sigma"
#> [9] "stan [✓]" "hat" "サイズ" "beta"
#> [13] "theta" "母集団" "ベクトル" "alpha"
#> [17] "シミュレーション" "トピック" "lambda" "sqrt"
#>
#> $ML
#> [1] "モデル" "パラメータ [✓]" "クラス" "主成分"
#> [5] "アルゴリズム [✓]" "テスト [✓]" "プロット" "データセット [✓]"
#> [9] "サンプル [4]" "ランダム" "boldsymbol" "グループ"
#> [13] "prophet" "クラスタリング" "サンプリング" "ドキュメント"
#> [17] "イベント" "カテゴリ" "model" "ポケモン"
Authoringの意図としては、RStudioやRMakrdownを使って文書を書き出したりするみたいな内容の記事を想定していましたが、RStudioやRのインストール方法やトラブルシュートみたいなトピックになっている気がします。
DataHandlingやVisualizationはおおむね期待した通りの感じです。また、MLの種語にした「テスト」というのは、意図としては「訓練用データとテスト用データに分割する」みたいな文脈における「テスト」であって、「単体テストを書こう」の「テスト」のことではありませんでした。このへんもだいたい上手くいっていそうです。
StatsとMLは、そもそもその境界が自分には上手く説明できないのですが、ここではStatsのほうが記事のなかで数式を書いているらしい気配を感じます。QiitaではTeX記法が使えるため、frac, hspaceとかboldsymbolとかあるのはTeX記法だったものがトークンとして抽出されたものです。
年ごとのトピックの割合
年ごとのトピックの割合の変化を見てみます。
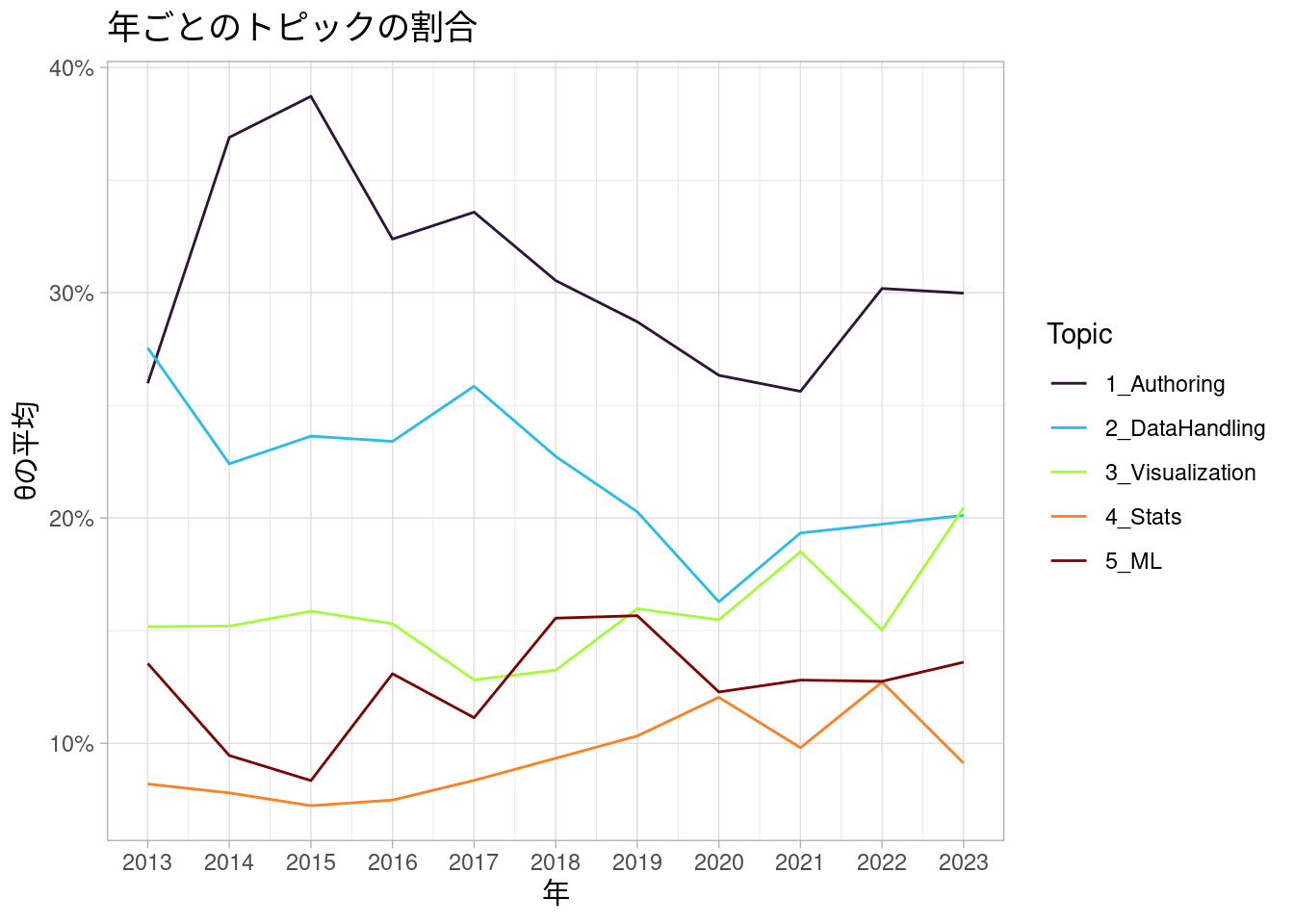
ぱっと見た感じ、Authoringトピックの記事の割合は2015年をピークに、2021年にかけてなんとなく減っているように見えます。
もっとも、2020年ごろにかけては投稿数が増え続けていたはずなので、これはトピックの流行り廃りのためというより、ちょっと多様な記事が書かれるようになった結果「RとRStudioのインストール方法を解説!」みたいな記事は相対的に減っていたみたいな話なのかもしれません。また、減ったとはいっても、依然として他のトピックより割合は高いままです。
DataHandlingは2017年より後ではやや割合が減ったようにも見えます。
たぶん関係ないですが、dplyrがv0.7.0になり、tidyevalがどうとか言い始めたのが2017年6月でした。dplyrとかrlangとかの便利だけどなんか難しい部分が出てきたことで、みんなよくわからない顔になり、DataHandlingトピックの記事が減ったのかもしれません(たぶん違うと思う。ちなみに、tidyevalということばは実はすでに過去のものになりつつあり、最近のdplyrのvignetteではtidy selectionとdata maskingということばによって駆逐されている)。
その他のトピックについては、何か明確なトレンドの変化があるようには見えません。あるのかもしれませんが、少なくとも、この図を見ただけではなんとも言えないような気がします。
BM25
StatsとMLについて、Okapi BM25を計算しつつ、もう少し詳しく確認してみます。
df |>
dplyr::filter(doc_id %in% quanteda::docid(dtm)) |>
dplyr::bind_cols(keyATM::top_topics(out)) |>
dplyr::select(doc_id, year, Rank1) |>
dplyr::right_join(
tidytext::tidy(dtm) |>
udpipe::document_term_frequencies(
document = "document",
term = "term"
) |>
udpipe::document_term_frequencies_statistics(),
by = "doc_id"
) |>
dplyr::filter(stringr::str_starts(Rank1, "[45]")) |>
dplyr::distinct(Rank1, term, tf_bm25) |>
dplyr::slice_max(tf_bm25, n = 20, by = Rank1) |>
dplyr::group_by(Rank1) |>
dplyr::group_map(\(x, grp) {
dplyr::pull(x, "term")
}) |>
purrr::set_names(c("4_Stats", "5_ML"))
#> $`4_Stats`
#> [1] "prml" "標準偏差" "急降下" "stan" "ランダム"
#> [6] "var" "サンプル" "モデル" "備忘録" "行列式"
#> [11] "det" "テスト" "平方根" "rstan" "パラメタ"
#> [16] "プログラム" "matlab" "標準偏差" "標準化" "iris"
#> [21] "モデル" "不適切"
#>
#> $`5_ML`
#> [1] "マニュアル" "ページ" "サイエンス" "factor"
#> [5] "交互作用" "サンプル" "参考文献" "false"
#> [9] "グループ" "モード" "tweet" "アイテム"
#> [13] "チャレンジ" "オプション" "ダミー" "モデル"
#> [17] "スクリプト" "csv" "アンケート" "mass"
#> [21] "リスク" "vif" "python" "ポスト"
#> [25] "グループ" "anova" "備忘録" "rpart"
#> [29] "gbm" "xgboost" "データ_フレーム" "glmnet"
BM25のスコアが大きい語から察するに、Statsは「PRML」に関する内容なり、統計や機械学習の理論的な部分についての「備忘録」のようなものとして書かれた記事や、何かの「プログラム」を自分で「Stan」で実装してみているような記事が少なくないのかなと思われます。
MLでも「マニュアル」や「参考文献」といった語がよく使われているようですが、MASS, rpart, gbm, xgboost, glmnetといった具体的なRパッケージ名が確認できることから、こちらはどちらかというと既存のRパッケージに実装されている関数の使い方を紹介しているような記事が多いのかなと思います。
実際、より難しめの内容になりそうなStatsよりもMLのほうがトピックの割合がやや大きかったですし、多くのRユーザーはその他のトピックを含む比較的ライトな内容の記事を書いているということが言えそうです。
まとめ
まあ、それはそうというか、インターネットの技術記事は書く側も読む側も、どちらかというと初心者であることのほうが多いはずですから、難しめの内容を自分で手を動かしながら実装しているような人はそもそも割合として少ないのでしょう。
一方で、少なくともQiitaに投稿される「R」の技術記事についていえば、その量は明らかに減っているというのも事実でした。それが「Rだから」なのか(たとえば、Pythonでデータ分析するようなQiita記事も減っているのか)はよくわからないものの、2020年のピーク時に年間700件近くあった投稿数は2023年では200件以下にまで落ち込んでいますし、投稿したユニークユーザー数もピーク時の半分以下になっています。
Statsのようなトピックの記事がだいたい10%程度の割合で書かれるのだとすると、70件くらいありそうだったものが、せいぜい20件くらいになっているだろうわけで、Qiitaで「R」タグが付けられていて、しかも数式が出てくるような記事は、とりわけ少なくなっていると言えそうです。
かといって、「みんなもっと難しめの記事も書くべきだ!」とか「記事を投稿してくれるRユーザーの裾野を広げていこう!」などと言うつもりはないですし、そもそもそういう情報をこれからQiita記事として増産していくべきなのかもわからないですが、私的な肌感覚として、Rの日本語コミュニティからのアウトプットはたしかに減っているような気はしています。
もちろん、Rはそこまでメジャーな言語ではないでしょうし、これがわりと通常の状態なのかもしれません。ただ、もうちょっといろんなレベルの日本語情報に容易にアクセスできるほうが、コミュニティの状態として好ましいとは思うので、個人的にはもう少しいろいろアウトプットしていきたいなと思いました。来年の抱負にします。