
秋元康の歌詞は何を書いてきたのか?構造的トピックモデルを用いた分析

この記事について
秋元康が書いた歌詞に対して、構造的トピックモデル(STM)を適用したり、いろいろ分析してみる。
この分析によって、秋元康の歌詞がこれまで何を書いてきたのか、あるいは、年代を経るにしたがって、秋元康によって書かれている歌詞の内容に変化はあるのかなどがわかるかもしれないし、まあわからないかもしれない。
使用するデータ
使用する歌詞のデータは、歌ネットでの検索結果に表示されるものをスクレイピングして用意した。秋元康が作詞している楽曲は、スクレイピングをした時点で、歌ネットに3,073曲あった。
ただし、歌ネットに登録されている楽曲は、歌っているアーティストや発表時のタイトルが違うとすべて異なる楽曲としてカウントされるため、この数にはまったく同じ内容で重複している歌詞が含まれる(たとえば『恋するフォーチュンクッキー/AKB48』vs『恋するフォーチュンクッキー(演歌バージョン)/岩佐美咲』など)。ちなみに、歌ネットには23曲の『川の流れのように』が登録されているらしい。
以下では、こうした歌詞の重複は無視し、他の楽曲の歌詞と重複した内容であってもすべて1曲としてカウントしている点に注意。
秋元康による作詞数は実に3,000曲超
データを眺めつつ、「秋元康はめちゃめちゃたくさん作詞をしている」ということを簡単に確認してみる。
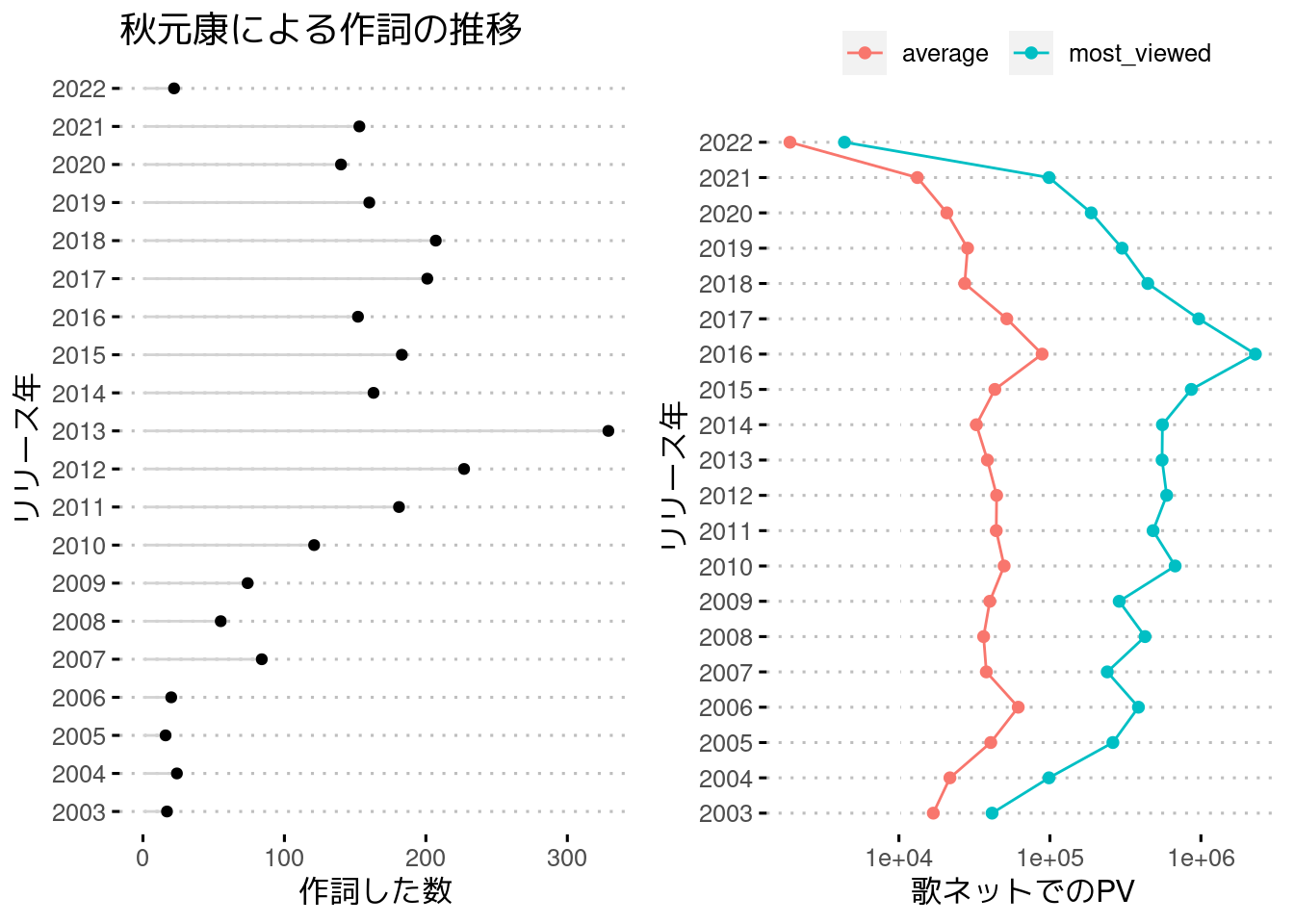
まず次のグラフは、過去20年にリリースされた、作詞が秋元康による楽曲数の推移(ここでのリリース年は年度ではなく、1月始まりの12月終わりのやつ)。
2013年にリリースされたものがとくに多く、この年リリースされたものとしては、329曲の歌詞を担当している。
2016年の『サイレントマジョリティー』がバズっている
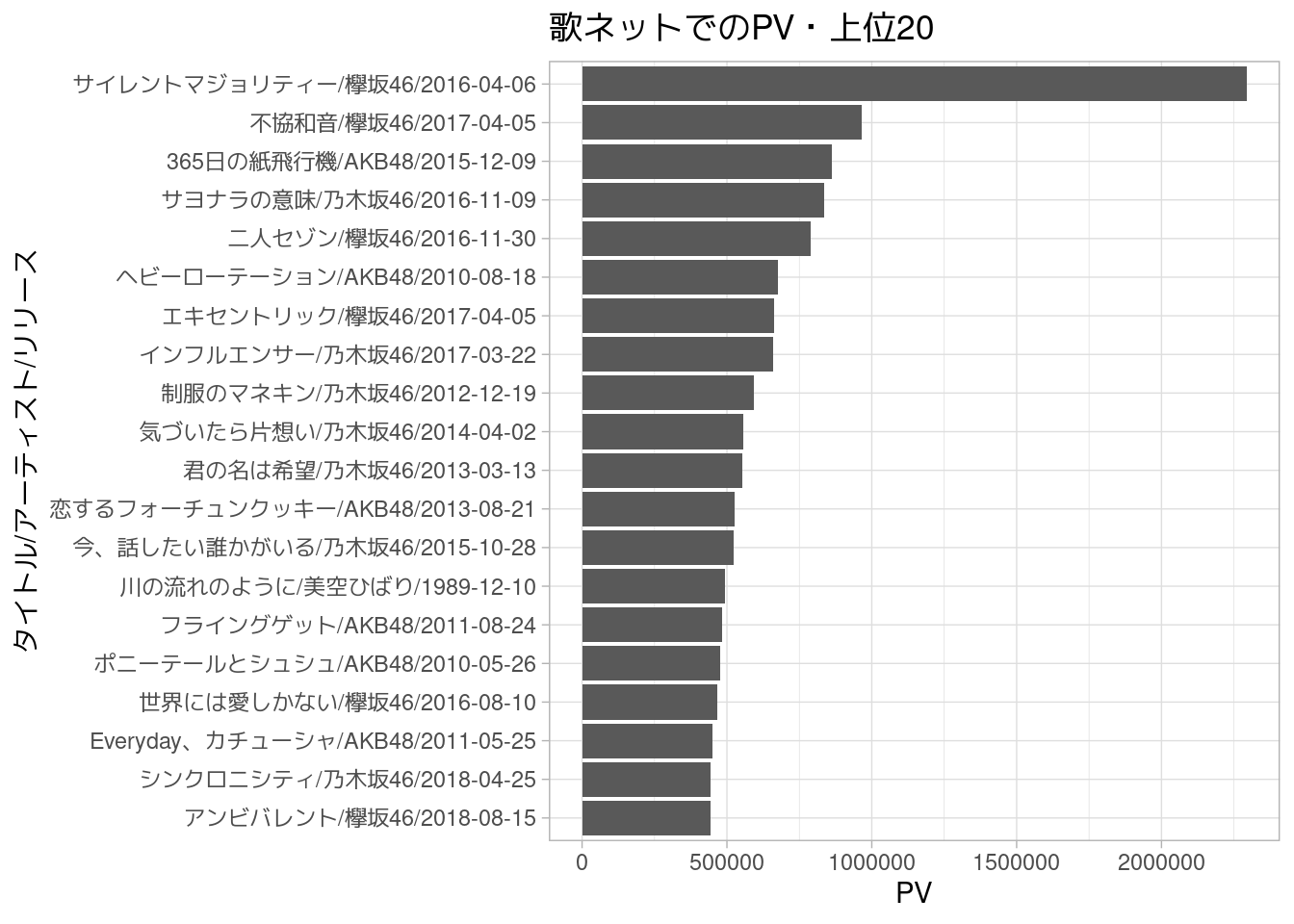
歌ネット上でとくによく閲覧されている楽曲としては、『サイレントマジョリティー』がおよそ2,294,000回閲覧されていて、かなり流行ったことがうかがえる。
インターネットで歌詞を閲覧する需要の時期的なものだったり、歌ネットが保持しているデータの都合なのかもしれないが、「AKBグループ」よりは、テン年代にリリースされた「坂道グループ」の楽曲の歌詞のほうがよく閲覧されている。
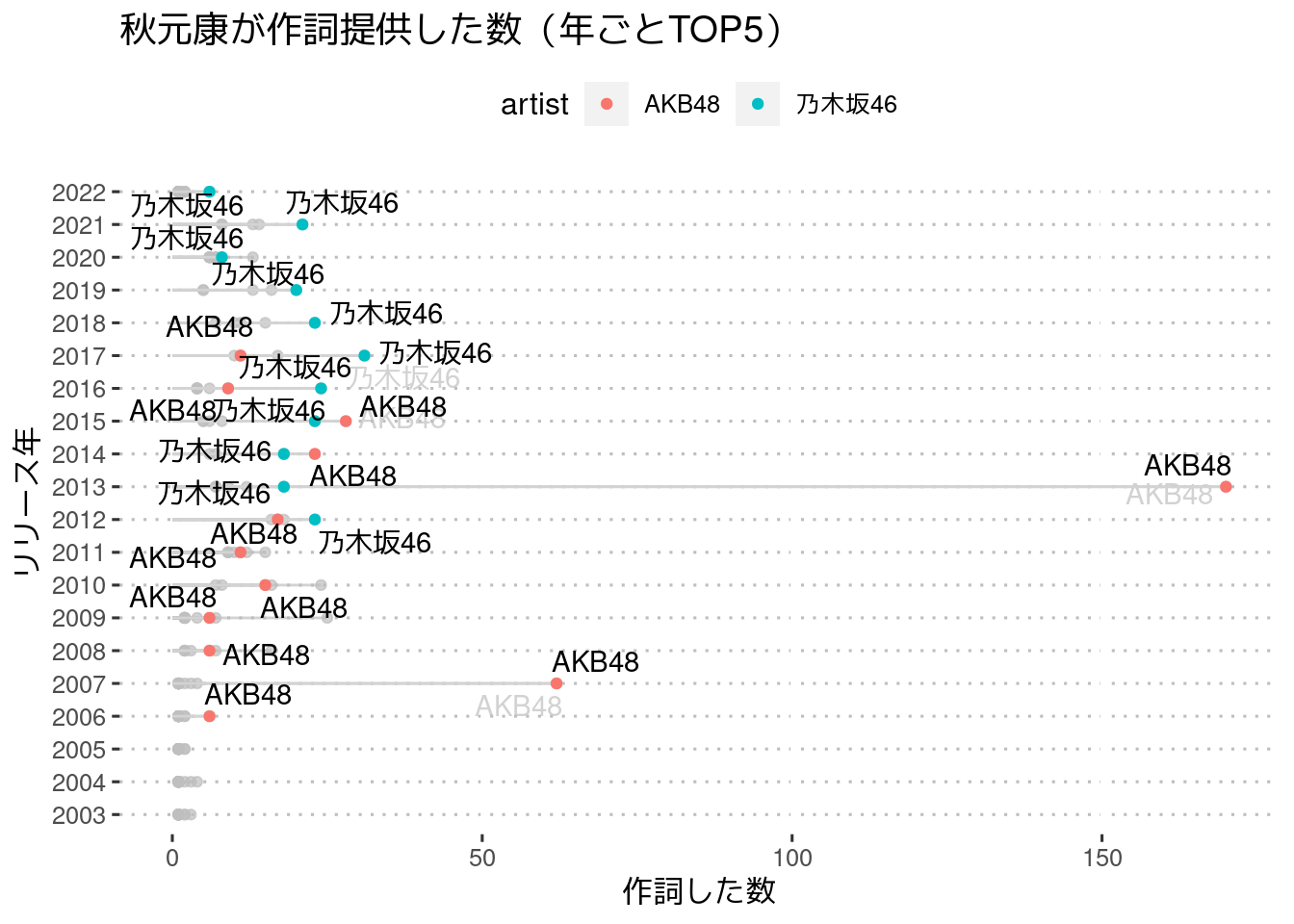
2016年から乃木坂の歌詞のほうがAKBの歌詞よりたくさん書かれている
2012年に乃木坂46が結成されたが、翌年の秋元康はAKB48関連の楽曲の歌詞をめちゃめちゃたくさん書いている。
しかしその後は、少なくとも秋元康による作詞数としては、2016年からずっと乃木坂46の作詞数のほうがAKB48の作詞数を上回っている。
これ以後、秋元康による作詞としては、乃木坂46へ歌詞提供したものが多い年が続いている。
データの前処理
以下の分析では、収集した秋元康による歌詞のうち、過去20年(2003年から2022年現在まで)のデータだけを使う。それでも2,500曲くらいあり、ここで実際に分析に用いたコーパスは、語彙数が3,634語、総トークン数が104,251語だった。
歌詞のテキストの前処理としては、MeCab(IPA辞書)で形態素解析を行い、辞書にある語については基本形、未知語については表層形を採用した分かち書きにしている。
形態素解析に先立っては、まず歌詞の連ごとに一文の扱いとしたうえで、各連を句点(「。」)で区切っている。また、行や全角スペースごとに読点(「、」)を挿入したうえで解析をして、これらの記号類については解析後に結果から除いている。
そのほか、秋元の書く歌詞中のカッコ書きには「私の席は後(うし)ろで」のような読み仮名をカッコに入れる用法のものと、「できるなら君と眺めたかった(その光)」のようないわゆるコーラスや合いの手などをカッコに入れる用法のものとがあるが、これらは機械的に判別することが難しいため、ここではカッコ書きの文字列はすべて削除している。
STMの適用にあたっては単語文書行列の語彙数(異なり語の数)を5,000語程度までに抑えることが推奨されている(もっと多くても実行できるが、収束が遅くなるとされる)ため、ストップワードなどを活用しながらいい感じにコーパスの語彙を削っている。ちなみに、ここで用いるストップワードには「恋」「恋愛」なども含まれているため、後の分析結果にはこれらの語彙は出てこない。
また、アーティストの列(artist)を「坂道グループ(名前に「46」が含まれるアーティスト)」「AKBグループ(名前に「48」が含まれるアーティスト)」「その他(その他全部)」の3つに単純化している。ただし、この処理は雑なので、「その他」のなかにも「AKBグループ」の派生ユニットなどが含まれてしまう場合がある(たとえば「フレンチキス」など)。したがって、「その他」だからといって、最近の女性アイドルグループ以外の楽曲であるという保証はとくにない。
コーパス中のアーティストの内訳は次のようになる。この20年のあいだでは「AKBグループ」の楽曲への歌詞提供数がもっとも多く、「坂道グループ」への歌詞提供数の3倍くらいあるらしい。
table(dtm@docvars$artist) |>
tibble::as_tibble(.name_repair = "minimal")
#> # A tibble: 3 × 2
#> `` n
#> <chr> <int>
#> 1 AKBグループ 1284
#> 2 その他 823
#> 3 坂道グループ 421
ちなみに、このデータを年ごとに集計すると、各年にリリースされた曲数にはややばらつきがある。2010年以後は例年100曲くらいはリリースされている曲(歌詞)があるが、この範囲だととくに2006年以前では、リリースされている曲数が少ない。
table(dtm@docvars$released) |>
tibble::as_tibble(.name_repair = "minimal")
#> # A tibble: 20 × 2
#> `` n
#> <chr> <int>
#> 1 2003 17
#> 2 2004 24
#> 3 2005 16
#> 4 2006 20
#> 5 2007 84
#> 6 2008 55
#> 7 2009 73
#> 8 2010 121
#> 9 2011 181
#> 10 2012 227
#> 11 2013 329
#> 12 2014 163
#> 13 2015 183
#> 14 2016 152
#> 15 2017 201
#> 16 2018 207
#> 17 2019 160
#> 18 2020 140
#> 19 2021 153
#> 20 2022 22
構造的トピックモデル(STM)
STMについて
構造的トピックモデル(STM:Structural Topic Modeling)は、トピック比率(Topic Proportions)を従属変数とする共変量Prevarence(X) と、各トピックにおける単語の確率分布(Topic Word Distribution)を従属変数とする共変量Content-covariates(Y)を組み込んでいるトピックモデルである。
適用例としては、トピック比率は経年変化するのではないかという関心から、たとえばXに出版年などを投入しつつ、Yに各トピックの分布に影響すると考えられる著者属性を投入するみたいな使い方ができる。
提案論文にもとづく、理論面の日本語解説としては、以下のレトリバのブログ記事がある。
また、以下の論文やブログ記事が資料として読みやすかった。
- 質的データの解析:―構造的トピックモデルを用いた「意味」の統計的解析―
- 戦後日本社会学のトピックダイナミクス
- 構造的トピックモデル(stm)を論文で使うための私なりのプロトコル - マイ・スウィート・ビーンズ
トピック数の決定・STMの適用
STMはR実装の{stm}パッケージを使った(雰囲気で使ったので、例によってどこか間違っているかもしれない)。
いちおう、3~20の範囲でよさそうなトピック数(K)をあらかじめ探索してみた(この計算はすごく時間がかかる)。
ここでは、トピック比率は歌詞が書かれた時期によって変化しうると仮定し、楽曲のリリース年をPrevarence(X)に投入する。また、各アーティストのコンセプトみたいなものは時期によらず不変であり、各トピックの分布に影響していると仮定して、アーティスト情報をContent-covariates(Y)に投入する。
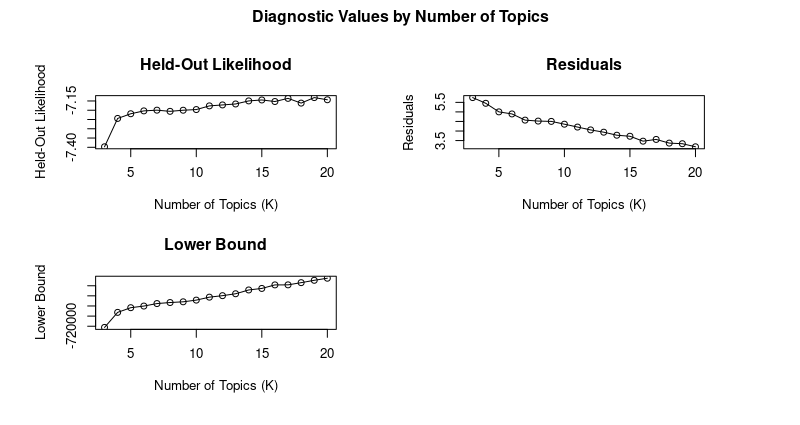
しかし、すごく時間がかかるわりに、held-out likelihoodはK=4くらいから、トピック数を増加させてもなだらかに推移していて、あまり変化がなかった。
したがってほぼほぼただの当てずっぽうなのだが、トピック数は少なすぎても多すぎても解釈が難しいことから、ここではK=10にして適用することにした。
用意したコーパスのリリース年については20年分の期間があるが、以下のようにすると、ここでは10次のスプラインを施したうえで変数として投入される。
mdout <-
stm::stm(dtm, K = 10, data = dtm@docvars,
prevalence =~ stm::s(released),
content =~ artist,
seed = 31415,
verbose = FALSE)
結果の解釈
トピック比率とリリース年による影響
まず先にリリース年の違いによる効果を確認する。
est <- stm::estimateEffect(~ stm::s(released), mdout, metadata = dtm@docvars)
summary(est)
#>
#> Call:
#> stm::estimateEffect(formula = ~stm::s(released), stmobj = mdout,
#> metadata = dtm@docvars)
#>
#>
#> Topic 1:
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.01710 0.02337 0.732 0.4645
#> stm::s(released)1 -0.01101 0.05431 -0.203 0.8393
#> stm::s(released)2 0.03679 0.03346 1.100 0.2715
#> stm::s(released)3 0.01831 0.02901 0.631 0.5279
#> stm::s(released)4 0.03370 0.02480 1.359 0.1743
#> stm::s(released)5 0.04212 0.03017 1.396 0.1628
#> stm::s(released)6 0.01487 0.02944 0.505 0.6135
#> stm::s(released)7 0.01626 0.02961 0.549 0.5828
#> stm::s(released)8 0.05544 0.03338 1.661 0.0968 .
#> stm::s(released)9 0.01414 0.03707 0.382 0.7028
#> stm::s(released)10 0.01682 0.03383 0.497 0.6191
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#>
#> Topic 2:
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.063855 0.048720 1.311 0.1901
#> stm::s(released)1 0.163971 0.106733 1.536 0.1246
#> stm::s(released)2 -0.007913 0.064759 -0.122 0.9028
#> stm::s(released)3 0.050393 0.058709 0.858 0.3908
#> stm::s(released)4 0.055698 0.051961 1.072 0.2839
#> stm::s(released)5 0.090711 0.060409 1.502 0.1333
#> stm::s(released)6 0.062506 0.061333 1.019 0.3082
#> stm::s(released)7 0.093832 0.058505 1.604 0.1089
#> stm::s(released)8 0.105813 0.066612 1.589 0.1123
#> stm::s(released)9 0.130353 0.073479 1.774 0.0762 .
#> stm::s(released)10 0.133509 0.072153 1.850 0.0644 .
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#>
#> Topic 3:
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.03684 0.03878 0.950 0.342
#> stm::s(released)1 0.02863 0.08774 0.326 0.744
#> stm::s(released)2 0.02549 0.05320 0.479 0.632
#> stm::s(released)3 0.05727 0.04775 1.199 0.230
#> stm::s(released)4 0.04548 0.04098 1.110 0.267
#> stm::s(released)5 0.03878 0.04872 0.796 0.426
#> stm::s(released)6 0.01822 0.04879 0.373 0.709
#> stm::s(released)7 0.07237 0.04535 1.596 0.111
#> stm::s(released)8 -0.01720 0.05237 -0.328 0.743
#> stm::s(released)9 0.09374 0.05874 1.596 0.111
#> stm::s(released)10 0.02585 0.05599 0.462 0.644
#>
#>
#> Topic 4:
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.06705 0.04628 1.449 0.1475
#> stm::s(released)1 -0.01293 0.10081 -0.128 0.8980
#> stm::s(released)2 -0.01005 0.06114 -0.164 0.8695
#> stm::s(released)3 0.05038 0.05466 0.922 0.3568
#> stm::s(released)4 0.04011 0.04983 0.805 0.4209
#> stm::s(released)5 0.01318 0.05670 0.232 0.8162
#> stm::s(released)6 0.05058 0.05922 0.854 0.3931
#> stm::s(released)7 0.10326 0.05458 1.892 0.0586 .
#> stm::s(released)8 0.11095 0.06435 1.724 0.0848 .
#> stm::s(released)9 0.15569 0.07085 2.197 0.0281 *
#> stm::s(released)10 0.05508 0.06888 0.800 0.4240
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#>
#> Topic 5:
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.133976 0.056635 2.366 0.0181 *
#> stm::s(released)1 -0.046770 0.125281 -0.373 0.7089
#> stm::s(released)2 -0.037278 0.066257 -0.563 0.5737
#> stm::s(released)3 0.062430 0.068121 0.916 0.3595
#> stm::s(released)4 -0.023212 0.059341 -0.391 0.6957
#> stm::s(released)5 0.017345 0.068110 0.255 0.7990
#> stm::s(released)6 -0.024028 0.067731 -0.355 0.7228
#> stm::s(released)7 0.008401 0.063732 0.132 0.8951
#> stm::s(released)8 -0.014653 0.071196 -0.206 0.8369
#> stm::s(released)9 -0.020841 0.078378 -0.266 0.7903
#> stm::s(released)10 -0.064921 0.079318 -0.818 0.4132
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#>
#> Topic 6:
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.14207 0.05096 2.788 0.00535 **
#> stm::s(released)1 -0.04291 0.11189 -0.384 0.70136
#> stm::s(released)2 0.14152 0.06707 2.110 0.03495 *
#> stm::s(released)3 -0.01221 0.06222 -0.196 0.84441
#> stm::s(released)4 0.02559 0.05298 0.483 0.62921
#> stm::s(released)5 0.03592 0.06118 0.587 0.55713
#> stm::s(released)6 0.08815 0.06576 1.340 0.18025
#> stm::s(released)7 -0.05692 0.05870 -0.970 0.33226
#> stm::s(released)8 0.06346 0.06803 0.933 0.35097
#> stm::s(released)9 -0.13446 0.07192 -1.870 0.06164 .
#> stm::s(released)10 0.08315 0.07246 1.148 0.25128
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#>
#> Topic 7:
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.27524 0.05276 5.217 1.97e-07 ***
#> stm::s(released)1 -0.09569 0.11187 -0.855 0.392432
#> stm::s(released)2 -0.16272 0.06513 -2.498 0.012545 *
#> stm::s(released)3 -0.15955 0.06127 -2.604 0.009263 **
#> stm::s(released)4 -0.16182 0.05318 -3.043 0.002368 **
#> stm::s(released)5 -0.19387 0.06179 -3.138 0.001723 **
#> stm::s(released)6 -0.18455 0.06298 -2.930 0.003419 **
#> stm::s(released)7 -0.12923 0.05953 -2.171 0.030026 *
#> stm::s(released)8 -0.23782 0.06250 -3.805 0.000145 ***
#> stm::s(released)9 -0.14062 0.07747 -1.815 0.069631 .
#> stm::s(released)10 -0.17391 0.06669 -2.608 0.009167 **
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#>
#> Topic 8:
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.0881580 0.0412496 2.137 0.0327 *
#> stm::s(released)1 0.0214684 0.0817748 0.263 0.7929
#> stm::s(released)2 -0.0275507 0.0482212 -0.571 0.5678
#> stm::s(released)3 -0.0360674 0.0455519 -0.792 0.4286
#> stm::s(released)4 0.0007397 0.0436830 0.017 0.9865
#> stm::s(released)5 -0.0115886 0.0467857 -0.248 0.8044
#> stm::s(released)6 -0.0625194 0.0471766 -1.325 0.1852
#> stm::s(released)7 -0.0436683 0.0473334 -0.923 0.3563
#> stm::s(released)8 -0.0957179 0.0477508 -2.005 0.0451 *
#> stm::s(released)9 -0.0013487 0.0536305 -0.025 0.9799
#> stm::s(released)10 -0.0589591 0.0535317 -1.101 0.2708
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#>
#> Topic 9:
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.123604 0.040450 3.056 0.00227 **
#> stm::s(released)1 -0.017805 0.086816 -0.205 0.83752
#> stm::s(released)2 -0.010717 0.052863 -0.203 0.83936
#> stm::s(released)3 -0.066124 0.047785 -1.384 0.16654
#> stm::s(released)4 -0.020771 0.043533 -0.477 0.63330
#> stm::s(released)5 -0.081402 0.047292 -1.721 0.08533 .
#> stm::s(released)6 -0.003721 0.048369 -0.077 0.93868
#> stm::s(released)7 -0.092593 0.046425 -1.994 0.04621 *
#> stm::s(released)8 -0.031716 0.052085 -0.609 0.54263
#> stm::s(released)9 -0.099229 0.058500 -1.696 0.08997 .
#> stm::s(released)10 -0.043200 0.057400 -0.753 0.45175
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#>
#> Topic 10:
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.050947 0.031281 1.629 0.104
#> stm::s(released)1 0.013463 0.069799 0.193 0.847
#> stm::s(released)2 0.053382 0.044189 1.208 0.227
#> stm::s(released)3 0.036455 0.037362 0.976 0.329
#> stm::s(released)4 0.005047 0.033081 0.153 0.879
#> stm::s(released)5 0.049957 0.039957 1.250 0.211
#> stm::s(released)6 0.042309 0.038569 1.097 0.273
#> stm::s(released)7 0.029702 0.039044 0.761 0.447
#> stm::s(released)8 0.061214 0.040557 1.509 0.131
#> stm::s(released)9 0.003411 0.045484 0.075 0.940
#> stm::s(released)10 0.028885 0.044769 0.645 0.519
7番はどうやら時間変化がありそう。年を経ると、トピック比率がなんとなく減少しているように見える。このトピックについては、年代による流行りがあるのかもしれない。一方で、そのほかのトピックについてはトピック比率に明確な変化はなさそうだった。
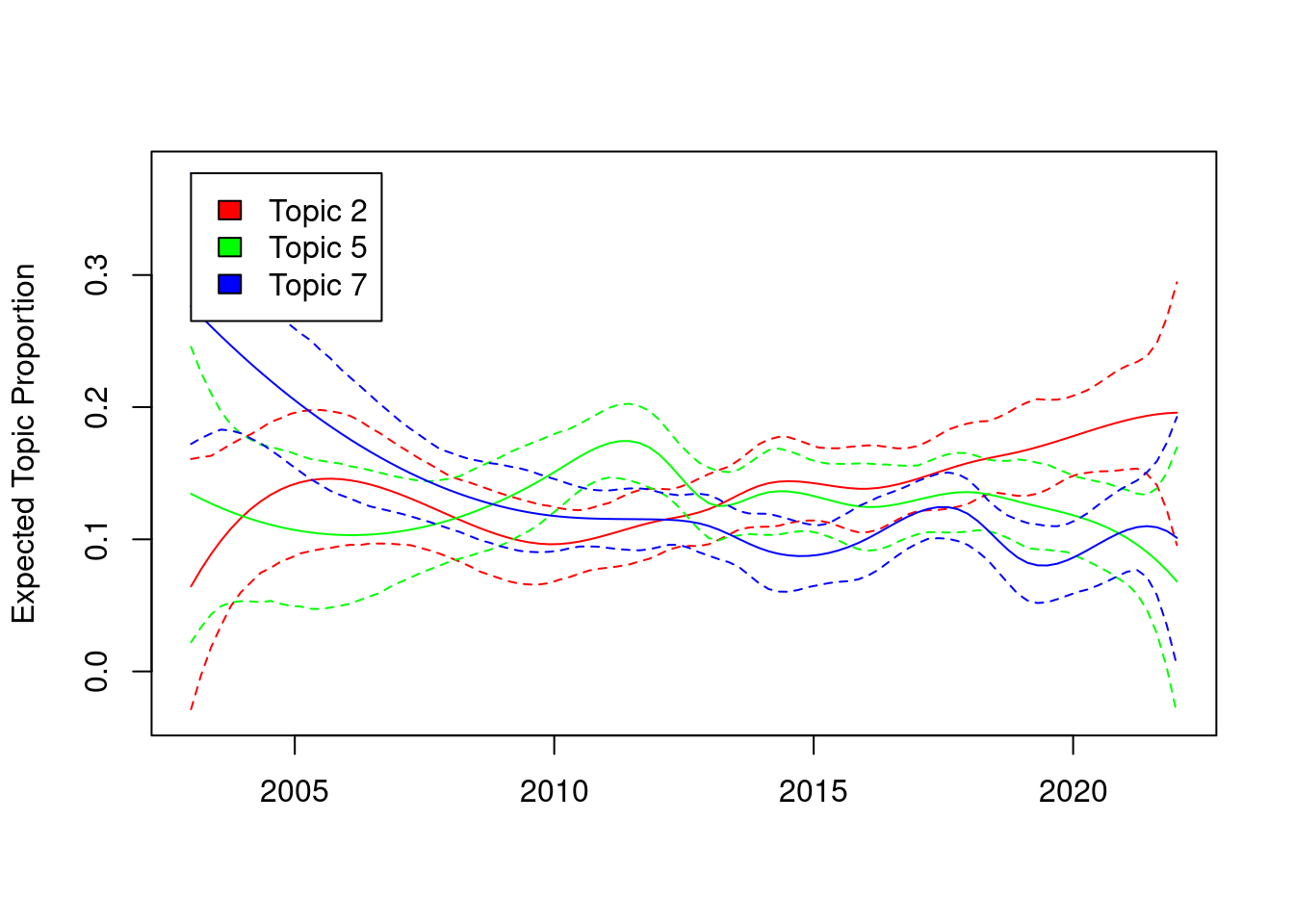
トピック比率としては、6番や2番が多く、1番や8番が少ない。以下では、トピック比率が1割を超えている6,2,5,4,7番のトピックに注目して見ていく。

トピックの中身
それぞれのトピックで出現確率が高いと推定される語を確認したところ、4番は「僕らはこういう存在になるよ」みたいな雰囲気を出していて、何かを決意している系のアイドルソングだろうと思われた。また、7番はコーパス中に複数含まれている『愛が生まれた日』が振り分けられていることから、なんとなく90年代っぽい調子で「愛」について語っているようなトピックなのかもしれない。

そのほか、やや無茶がある気もするが、6,2,5,4,7番はそれぞれ次のようなトピックとして解釈するとよさそうだった。
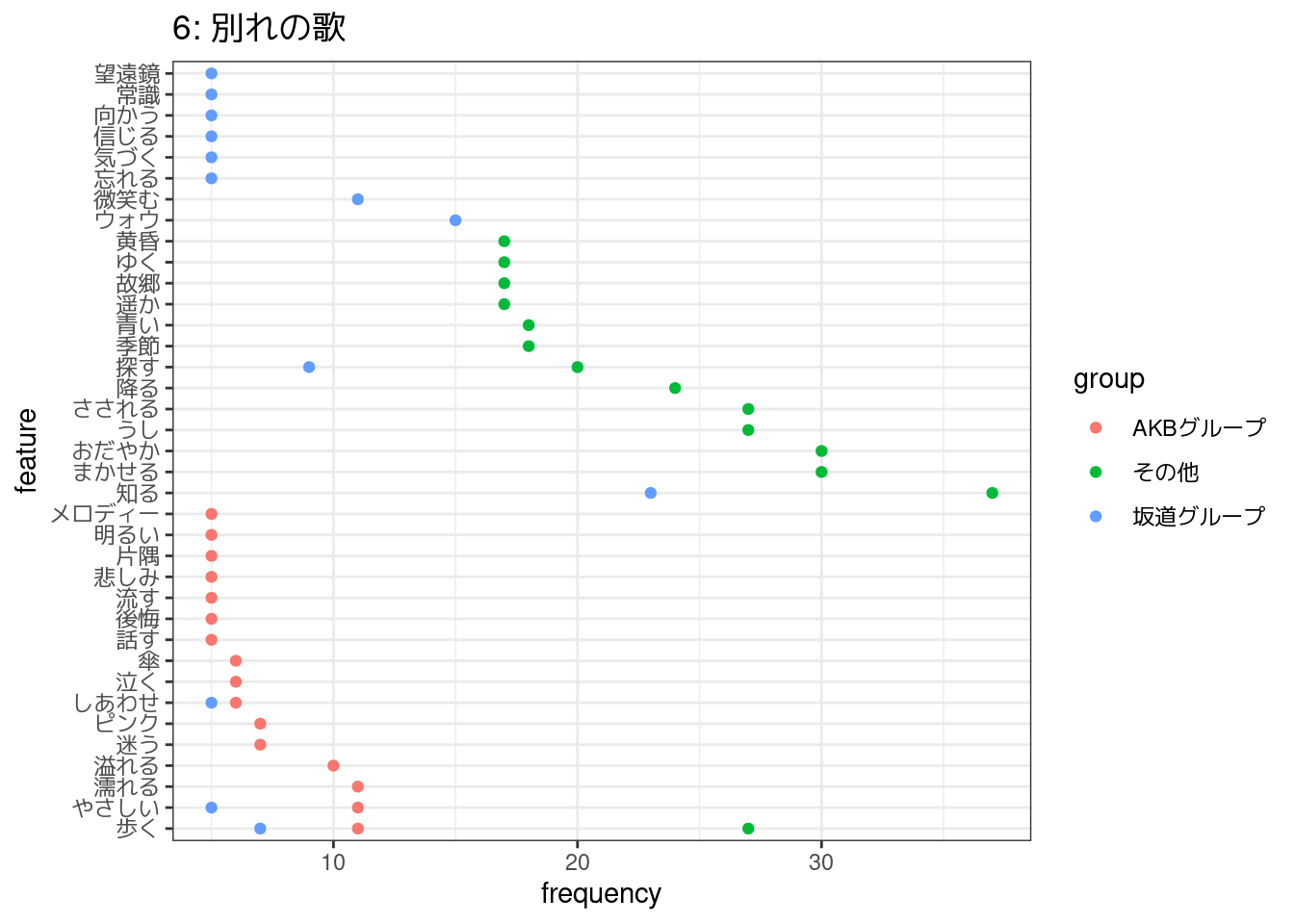
- 6: 別れの歌
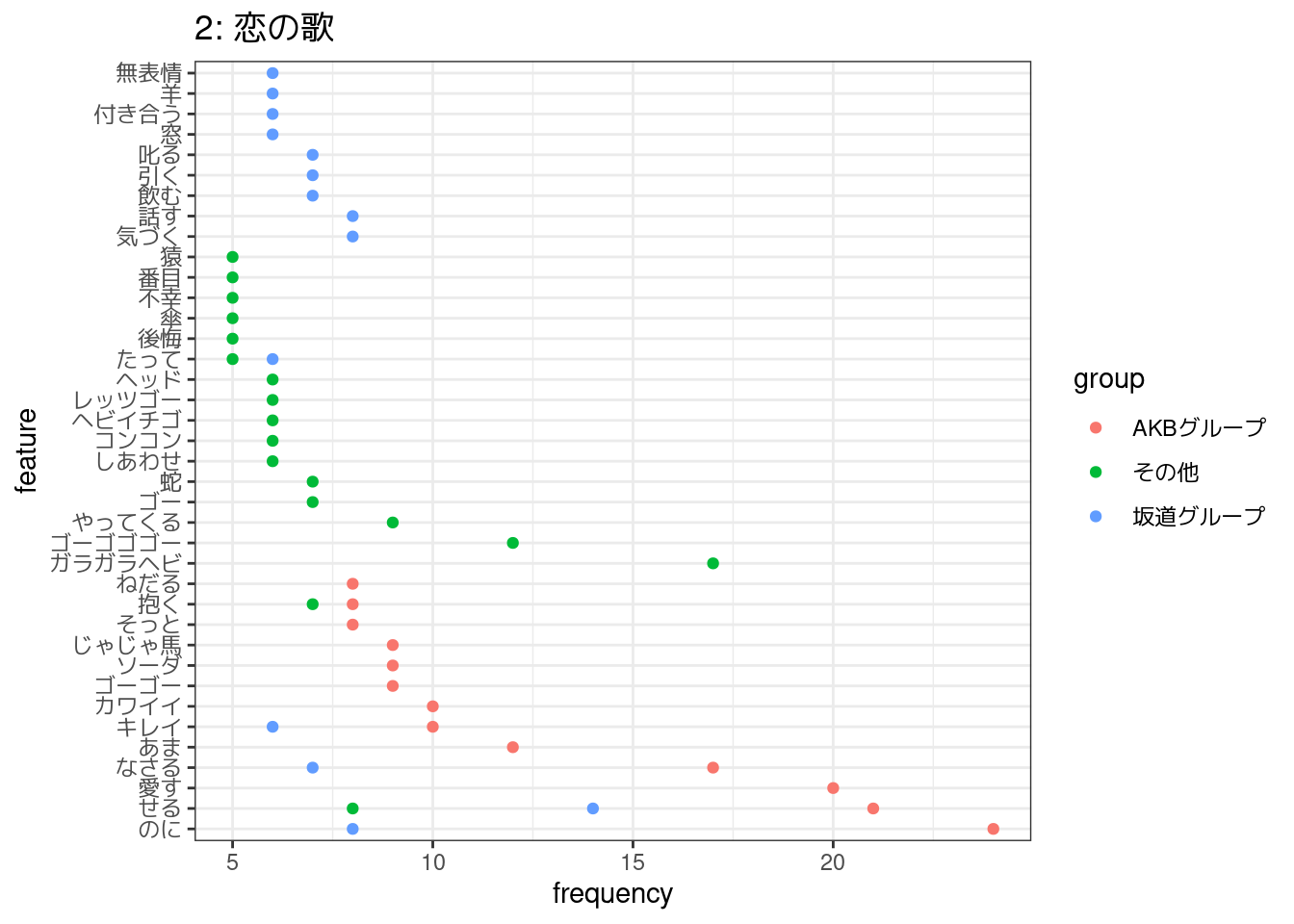
- 2: 恋の歌
- 4: 決意の歌
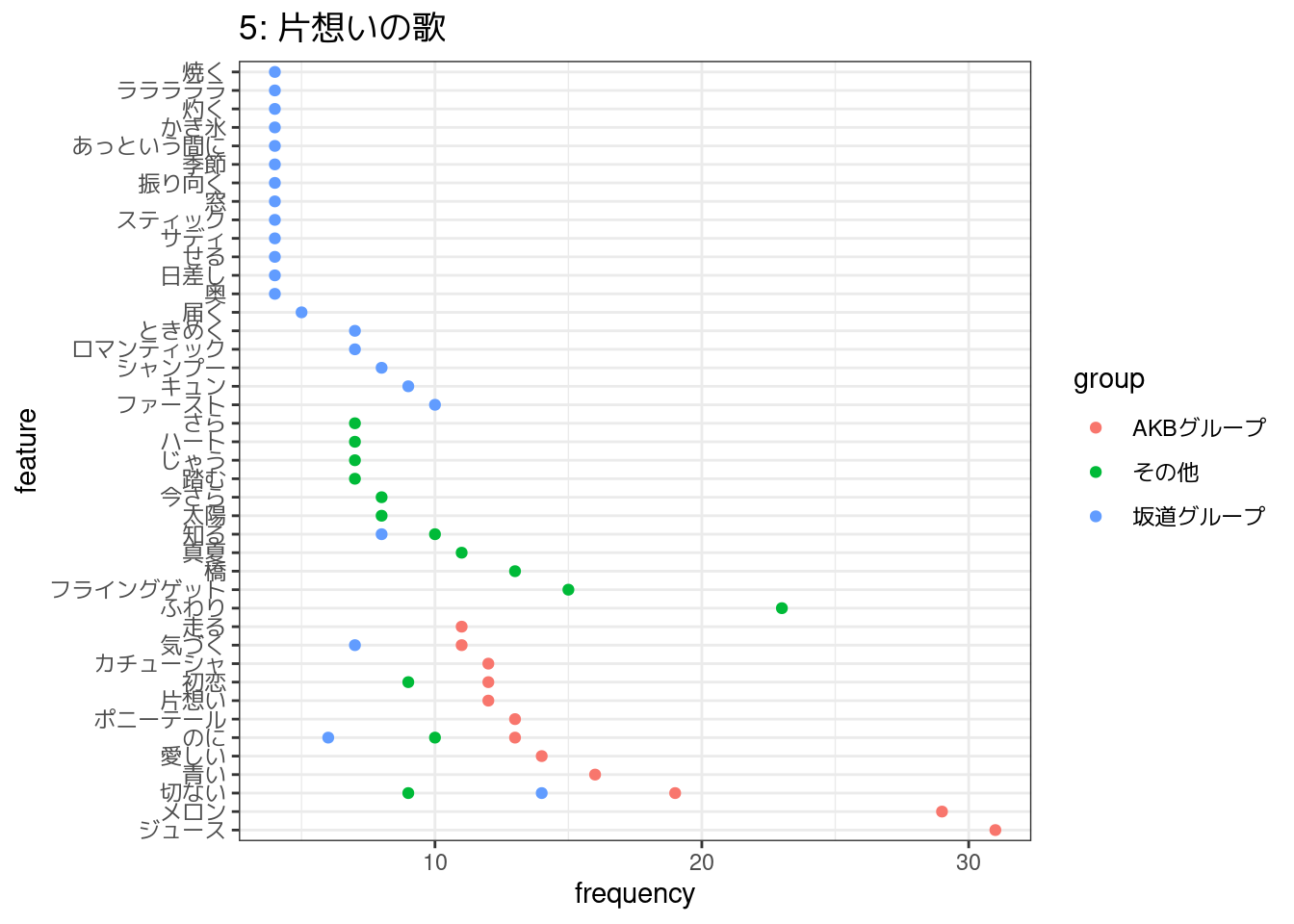
- 5: 片想いの歌
- 7: 愛の歌
トピックごとの語彙
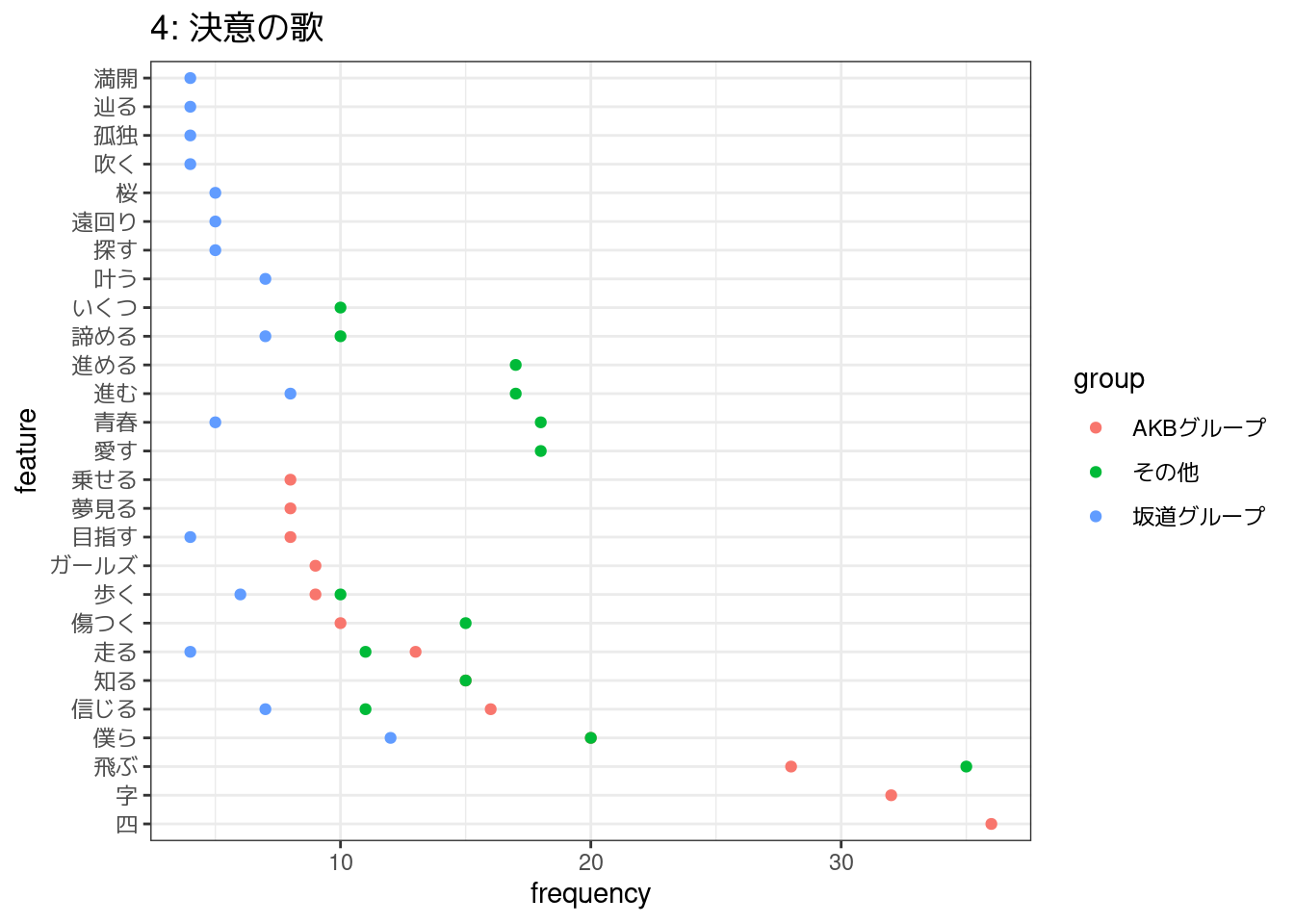
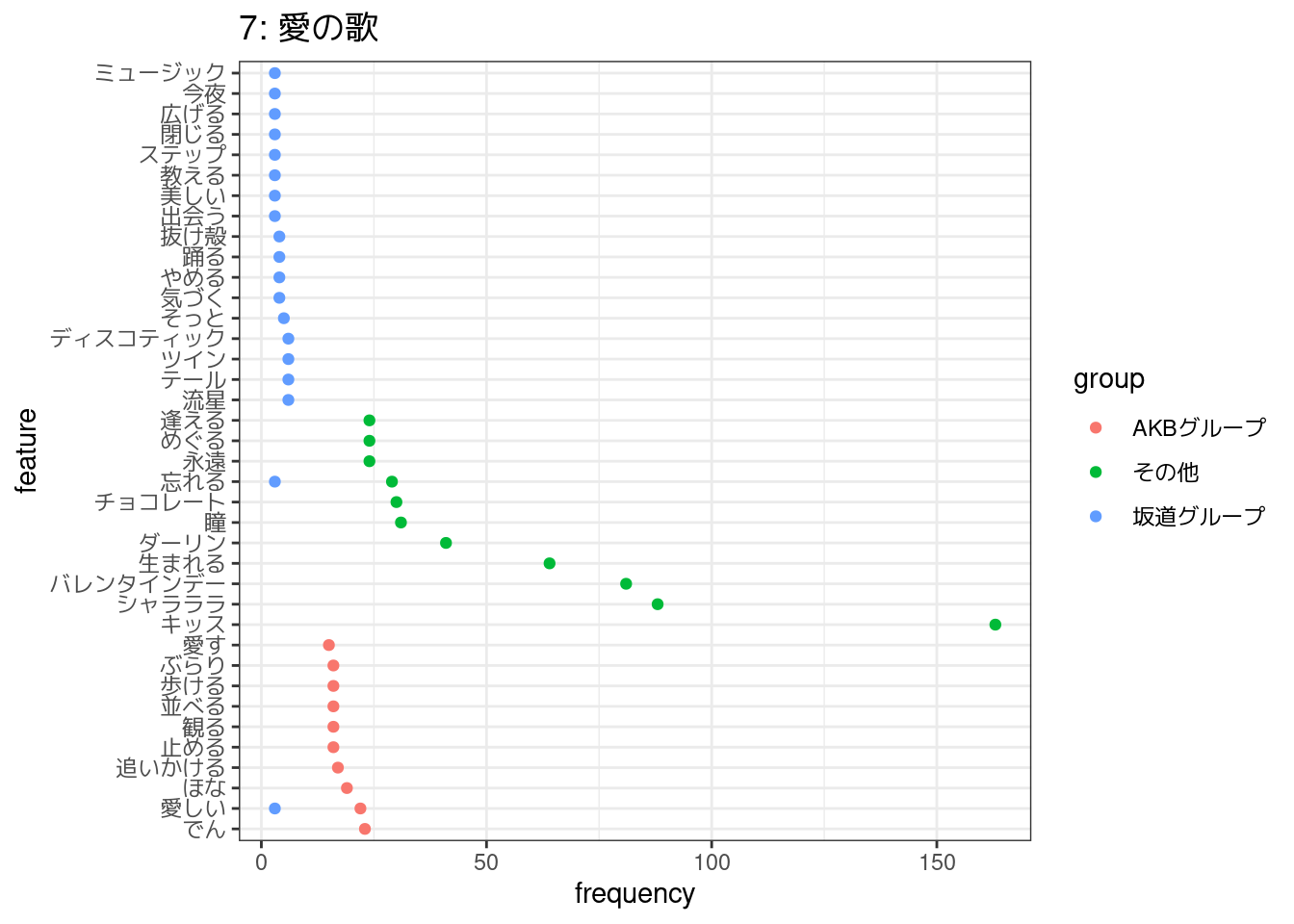
6,2,5,4,7番の5つのトピックについて、それぞれに関連していると考えられる歌詞をコーパスから50件ずつを目安に抽出し、各トピック・アーティストごとによく使われている語彙を集計して図示した。
7:愛の歌は「バレンタインデー」について歌っている歌詞が多そう。そもそもバレンタインソングなんて同じアーティストが何曲も出すものではなさそうだし、そうした事情からか、「バレンタインデー」について歌っている歌詞は「その他」のアーティストのものに偏っているように見える。
4:決意の歌については、アーティストによって使われる語彙が互いに重なりあっていて、アーティストによらず比較的一貫した歌われ方をしているように見える。
その一方で、そのほかのトピックは、アーティストごとによく使われている語彙にあまり重なりがなく、機械的には同じトピックに属するものと推定されていても、アーティストによって異なる歌われ方をしているのかもしれない。
7:愛の歌は減っているのか
坂道グループは「愛しい」とか言わなそう?
7:愛の歌については、トピック比率がリリース年によって変化していそうで、どうやら年代を経るにしたがってトピック比率としてゆるく減少しているようだった。
たしかに、テン年代後半以降に「AKBグループ」と入れ替わるようにリリースを増やしている「坂道グループ」では、比較的グループとしてのコンセプトがはっきりしている感があるので、イメージとしてもあんまり「愛しい」とか「愛す」とか言わなそうな気もする。
実際に、トピックとは関係なく全体を通じて「愛しい」「愛す」が含まれている歌詞をコーパスから探してみても、「坂道グループ」では頻度がやや少ないことが確認できる。「坂道グループ」の楽曲はその数がそもそも少ないので、「AKBグループ」や「その他」よりも任意の語彙が出現しづらいという事情があるものの、やはり「坂道グループ」は「愛しい」とか「愛す」とかはあまり言わないのではないだろうか。
count_w <-
\(word) {
tbl |>
dplyr::mutate(
artist = dplyr::case_when(
stringr::str_detect(artist, "46") ~ "坂道グループ",
stringr::str_detect(artist, "48") ~ "AKBグループ",
TRUE ~ "その他"
),
released = lubridate::year(released)
) |>
dplyr::filter(released > 2002) |>
dplyr::filter(stringr::str_detect(lyric, word)) |>
dplyr::count(artist)
}
count_w("愛しい")
#> # A tibble: 3 × 2
#> artist n
#> <chr> <int>
#> 1 AKBグループ 14
#> 2 その他 23
#> 3 坂道グループ 4
count_w("愛す")
#> # A tibble: 3 × 2
#> artist n
#> <chr> <int>
#> 1 AKBグループ 20
#> 2 その他 31
#> 3 坂道グループ 9
また、先ほどの各トピックについて50件を目安に抽出したデータ中では「坂道グループ」の7:愛の歌は5曲と比較的少なかったことからも、近年では秋元康から「坂道グループ」への歌詞提供が相対的に増えている一方で、「坂道グループ」では7:愛の歌はあまり歌われないために、秋元康が書く歌詞のトピック比率として7:愛の歌は減っているみたいなことはあるのかもしれない。
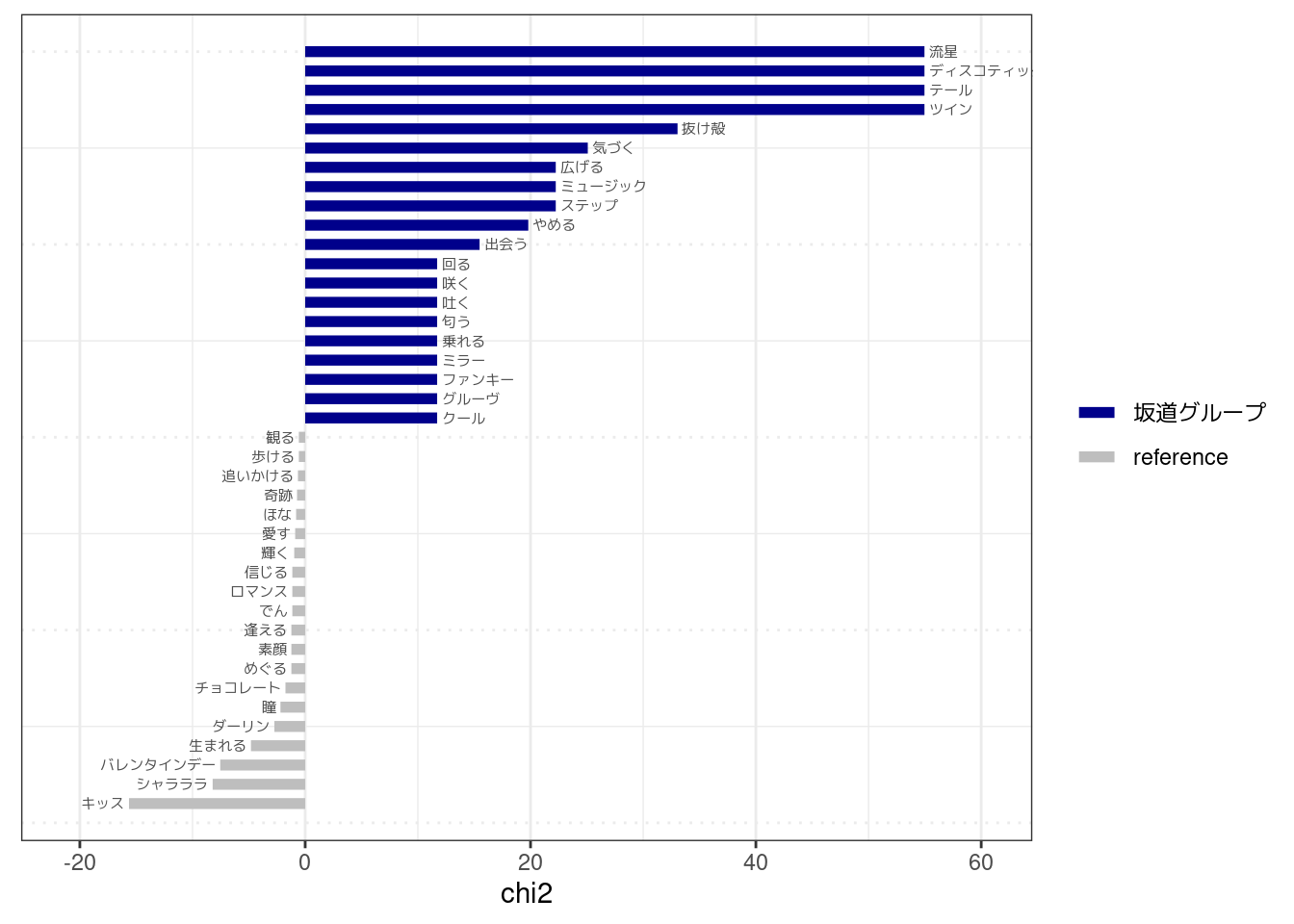
同じトピックでもアーティストによって特徴語が違うかも
ちなみに、ここで「坂道グループ」の7:愛の歌として抽出されているのは以下の5曲だが(これらのどのへんが愛の歌かとかは深く考えないでおく)、7:愛の歌のトピック内で見ても、「AKBグループ」「その他」とでは特徴語がやや違う印象を受ける。上でもすでに指摘したが、同じトピック内であっても、アーティストによって歌われ方が違うみたいなことはわりとあるのかもしれない。
- 『今夜はええやん/吉本坂46』
- 『三角の空き地/乃木坂46』
- 『流星ディスコティック/乃木坂46』
- 『コウモリよ/乃木坂46』
- 『ツインテールはもうしない/まゆ坂46』
わかったかもしれないこと
だいぶ確証バイアスっぽい話の進め方だったけど、この記事の分析から、次のようなことがわかったのかもしれない。
- 「愛しい」とかを歌うタイプの「愛」がテーマの歌は、「坂道グループ」はあまり歌わないものであることから、減っているのかもしれない
- 4:決意の歌については、わりとみんな似たような歌詞になりがちなのかも
- そのほかのトピックでは、同じトピックであっても、歌詞を歌うアーティストによって若干関心が異なることがあるのかもしれない
後知恵っぽい話として、昨今の女性アイドルシーン全体を見ても、しばしばグループのコンセプトが変わりつつあるとする見方があったりする。特にこのコロナ禍にあって、「じっくり聴かせるような曲を増やしたり、ダンスを隅々まで堪能できるように振付をブラッシュアップするなど、“鑑賞”という部分に重点を置いて制作がなされているグループも出てきた」(「NMB48 小嶋花梨ら、コロナ禍においてコンテンツに力を入れるアイドル達 - Real Sound|リアルサウンド」)という見解があり、直近のAKB48についてはダンスに注力したり、アーティスト性の高い楽曲を志向したりしていることから、「モー娘。化」しているのではという意見もある。
もっとも、コロナ禍はたかだかこの2年余りの出来事なので、この分析で捉えられたかもしれない変化がこうした女性アイドルシーン全体の転換を反映するものとは考えにくい。しかし、そのときの時勢によって楽曲のコンセプトに流行り廃りがあるという見方はあながち的外れではなく、もうちょっと工夫すればそうした変化を計量的な分析でもわかりやすく捉えられるのではないかなとは感じた。